ELVM で C コンパイラをポーティングしてみよう(Vim script 編)
この記事は Vim アドベントカレンダー 2016 の2日目の記事です.
先々月に ピュア Vim script な C コンパイラを公開しました.
この記事では 8cc.vim で用いた,ELVM を利用して 8cc という C コンパイラを Vim script にポーティング(移植)する方法についてチュートリアル的に解説してみます.
まずは登場人物から説明します.
8cc
8cc は C で書かれたコンパイラです.C コンパイラとしては小さく(1万行ぐらい),コードが読みやすいです.小さい割に C11 をサポートしており,セルフホスト(自分自身のコードをコンパイルできる)されています.まさか作者も今回説明するような用途に使われることになるとは思わなかったと思います.
ELVM
ELVM とは Esoteric Langage Virtual Machine の略で,C で書かれたコードを何らかのターゲット(Ruby や JavaScript, BrainFxxk など)のコードに変換するためのコンパイラ基盤です.構造的にはフロントエンドとバックエンドに分かれていて,まずはフロントエンドで C のコードを中間表現に変換し,次にバックエンドでその中間表現を何らかのターゲットのコードに変換します.
フロントエンド部分は 8cc を fork して改造したものです.8cc は元は x86-64 向けの C コンパイラですが,コード生成部分に手を加え,独自の中間表現である EIR (ELVM IR) という形式のコードを生成するように書き換えられています.EIR は非常にシンプルな数種類の命令のみの言語です.
バックエンド部分は elc というプログラムで,EIR のコードを受け取り,そのコードを各ターゲットのコードに変換します.Ruby や JavaScript などの各ターゲットごとに EIR の各命令をどう変換するかのロジックが C で記述されています.

よくご存知の方は,この構成が LLVM に似ていることに気づくかもしれません.実際 ELVM のアーキテクチャは LLVM を参考にしてつくられています.大きな違いは中間表現のシンプルさです.中間表現をシンプルにすることにより,中間表現→各ターゲットへの変換をとても簡単にしています.これは,ELVM が C で書いたコードを EsoLangVM の名の通り 難解プログラミング言語 にコンパイルすることを意図しているためです.これにより,難解言語を直接書かなくても C のコードを書くだけで後はコンパイラが変換してくれるようになり便利*1ですね.
中間表現が十分シンプルでないと,難解言語に変換するのが困難になってしまうというわけです.その代わり,フロントエンドを追加する(C 以外の別の言語のコードを変換できるようにする)のは大変ですが,今回はフロントエンドを触らないので問題ありません.
ここが ELVM の面白いところです.バックエンドのターゲット追加が簡単に行えるため,C 言語のコードから自分の好きな言語のコードへのコンパイラを簡単に書くことができます.
さらに,8cc は元々セルフホストされた C コンパイラです.なので,ELVM は自分自身をコンパイルすることができます.例えば Ruby を例に取ると
- Ruby をターゲットとする ELVM バックエンドを書く(C 言語)
- C → Ruby にコンパイルできるようになる(コンパイラ (ELVM) は C 言語)
- Ruby で書かれた ELVM が手に入る(= Ruby で動く C から各ターゲットへのコンパイラ)
という過程により,ピュア Ruby で書かれた C コンパイラが手に入ります.
下記のリンクのスライドでは作者の shinh さん本人による解説があります.
http://shinh.skr.jp/slide/elvm/000.html
また,JavaScript バックエンドはブラウザで直接実行することもできます.下記の playground で実際にいじってみることができます.
http://shinh.skr.jp/elvm/8cc.js.html
ELVM の Vim script バックエンドをつくってみる
それでは上記の要領で Vim script で書かれた C → Vim script へのコンパイラをつくってみましょう.8cc は Linux 向けのコンパイラのため,ELVM も Linux でしかビルドできませんので気をつけてください.僕は Ubuntu 16.04 を使いました.何か別の言語へのコンパイラをつくりたい場合は適宜 Vim script をその言語に読み替えてください.
まずは ELVM をクローンしてきます.
git clone https://github.com/shinh/elvm.git
バックエンドの各ターゲット向けのコードを生成する処理は target ディレクトリ内にあります.たとえば target/ruby.c は Ruby をターゲットにした際の処理が記述されています.
まずは自分がこれから追加するターゲットの名前を決めます.すでに vim はあるので,今回は viml とします.下記のように Makefile と target/elc.c にこれから追加するターゲット名を書きます.elc.c はバックエンドの本体で,引数などからどのターゲットに EIR を変換するかを決めて変換する処理が書かれています.
diff --git a/Makefile b/Makefile index 5dea604..c1c87f6 100644 --- a/Makefile +++ b/Makefile @@ -61,7 +61,7 @@ COBJS := $(addprefix out/,$(notdir $(CSRCS:.c=.o))) $(COBJS): out/%.o: ir/%.c $(CC) -c -I. $(CFLAGS) $< -o $@ -ELC_SRCS := elc.c util.c rb.c py.c tf.c js.c php.c el.c vim.c tex.c cl.c sh.c sed.c java.c swift.c c.c cpp.c x86.c i.c ws.c piet.c pietasm.c bef.c bf.c unl.c +ELC_SRCS := elc.c util.c rb.c py.c tf.c js.c php.c el.c vim.c viml.c tex.c cl.c sh.c sed.c java.c swift.c c.c cpp.c x86.c i.c ws.c piet.c pietasm.c bef.c bf.c unl.c ELC_SRCS := $(addprefix target/,$(ELC_SRCS)) COBJS := $(addprefix out/,$(notdir $(ELC_SRCS:.c=.o))) $(COBJS): out/%.o: target/%.c @@ -173,6 +173,11 @@ build: $(TEST_RESULTS) # Targets +TARGET := viml +RUNNER := f(){ vim -X -N -u NONE -i NONE -V1 -e --cmd "source $1 | qall!" }; f +TOOL := vim +include target.mk + TARGET := rb RUNNER := ruby include target.mk
- elc.c
diff --git a/target/elc.c b/target/elc.c index 80b08c9..030a5f8 100644 --- a/target/elc.c +++ b/target/elc.c @@ -12,6 +12,7 @@ void target_js(Module* module); void target_php(Module* module); void target_el(Module* module); void target_vim(Module* module); +void target_viml(Module* module); void target_tex(Module* module); void target_cl(Module* module); void target_sh(Module* module); @@ -45,6 +46,8 @@ static target_func_t get_target_func(const char* ext) { return target_el; } else if (!strcmp(ext, "vim")) { return target_vim; + } else if (!strcmp(ext, "viml")) { + return target_viml; } else if (!strcmp(ext, "tex")) { return target_tex; } else if (!strcmp(ext, "cl")) {
ここで,まずは試しに make してみます.初回は 8cc の clone やビルドなどが走ります.依存関係が足りない場合があるので,適宜インストールします.最終的に target/viml.c が無いと言われたら OK です.
次に EIR から Vim script への変換を行う処理を書いていきます.
EIR の仕様はリポジトリ内にドキュメントがあります.仕様はとても小さいので,ざっと目を通しておきます.
target/*.c の中の自分がいちばん得意な処理系のターゲット実装をコピーしてくるのが良さそうです.例えば Ruby のターゲット実装を元にする場合は下記のようにコピーして,vim.c を書き換えていきます.
$ cp target/rb.c target/viml.c
ターゲットの実装コードは下記のような部分に分かれています.
- 初期化処理
- EIR の命令に対応するコード生成
- と 2. を使って全体のコード生成
初期化処理
emit_line という関数でコードを生成していきます.名前の通り,printf 形式の引数でフォーマットされた文字列を1行のコードとして出力するだけです.
// a〜d の4つの汎用レジスタとプログラムカウンタやスタックポインタなどのレジスタ定義 static const char* REG_NAMES_VIM[] = { "s:a", "s:b", "s:c", "s:d", "s:bp", "s:sp", "s:pc" }; // 初期化処理.コード生成時に最初に一度だけ呼ばれる static void init_state_viml(Data* data) { reg_names = REG_NAMES_VIM; // すべてのレジスタを 0 で初期化 for (int i = 0; i < 7; i++) { emit_line("let %s = 0", reg_names[i]); } // メモリはリストを使って表す.2^24 = 16777216 分の領域を 0 で初期化 emit_line("let s:mem = repeat([0], 16777216)"); // C プログラムのデータ部分をメモリにロードする処理 for (int mp = 0; data; data = data->next, mp++) { if (data->v) { emit_line("let s:mem[%d] = %d", mp, data->v); } } }
レジスタおよびメモリ領域のゼロ初期化と,メモリへのデータの読み出しをしています.
EIR の命令に対応するコードの生成
ドキュメント にある通り,EIR には MOV (値のコピー),ADD(加算),SUB(減算),LOAD(メモリから値を読む),STORE(メモリに値を書き込む),GETC(1文字標準入力から読む),PUTC(1文字標準出力に書く),EXIT(プログラム終了)... などなどの22の命令があります.
ここではいくつかのヘルパ関数が使われています.src_str(inst) は命令 inst のオペランドで指定されている src の値(即値 or レジスタアクセス)を文字列化してくれる関数です.
また,inst->dst.reg には命令の dst オペランドのレジスタの添字が入っています.これを使って reg_names[inst->dst.reg] とすることで,Vim script でレジスタを表す変数が得られます(e.g. 0 -> s:a)
switch 文で分岐して,それぞれの命令に対応する Vim script のコードを生成します.
static void viml_emit_inst(Inst* inst) { switch (inst->op) { // 値のコピー. // // e.g. let s:d = 4 case MOV: emit_line("let %s = %s", reg_names[inst->dst.reg], src_str(inst)); break; // 値の加算 // 加算結果がオーバーフローしているかもしれない (ワード長は24bit) ので,and を取ります. // e.g. let s:b = and((s:a + s:c), 16777216) case ADD: emit_line("let %s = and((%s + %s), " UINT_MAX_STR ")", reg_names[inst->dst.reg], reg_names[inst->dst.reg], src_str(inst)); break; // 値の減算 case SUB: emit_line("let %s = and((%s - %s), " UINT_MAX_STR ")", reg_names[inst->dst.reg], reg_names[inst->dst.reg], src_str(inst)); break; // 値のメモリからの読み出し // e.g. let s:a = s:mem[s:b] case LOAD: emit_line("let %s = s:mem[%s]", reg_names[inst->dst.reg], src_str(inst)); break; // メモリへの書き込み // e.g. let s:mem[s:a] = s:d case STORE: emit_line("let s:mem[%s] = %s", src_str(inst), reg_names[inst->dst.reg]); break; // 1文字書き出す. :echon を使ってメッセージとして出力 // e.g. echon nr2char(64) case PUTC: emit_line("echon nr2char(%s)", src_str(inst)); break; // 1文字入力を受け取る // getchar() を使ってユーザから入力を受け取る // getchar() は基本的に入力された1バイトを数値として返すが,特別な場合に文字列を // 返したりするので,数値でないときは 0 (読めなかった)としてレジスタに書き込む // e.g. // let l:c = getchar() // let s:a = type(l:c) == type(0) ? l:c : 0 case GETC: emit_line("let l:c = getchar()"); emit_line("let %s = type(l:c) == type(0) ? l:c : 0", reg_names[inst->dst.reg]); break; // プログラムを終了する // Vim script にはその場でプログラムを終了する方法は無い(:finish は :source で読み込まれた // 場合などに使えないので,1 を返したときはプログラム終了として呼び出し元でハンドルする case EXIT: emit_line("return 1"); break; case DUMP: break; // 各種比較命令. // cmp_str() ヘルパ関数が比較関数を生成してくれるので,手で書く必要はない (引数の "1" は真値) // e.g. let s:a = s:a >= s:b ? 1 : 0 case EQ: case NE: case LT: case GT: case LE: case GE: emit_line("let %s = %s ? 1 : 0", reg_names[inst->dst.reg], cmp_str(inst, "1")); break; // ジャンプ命令. // 条件を満たした時ジャンプする(プログラムカウンタに特定のアドレスを書き込む) case JEQ: case JNE: case JLT: case JGT: case JLE: case JGE: case JMP: emit_line("if %s", cmp_str(inst, "1")); inc_indent(); emit_line("let s:pc = %s - 1", value_str(&inst->jmp)); dec_indent(); emit_line("endif"); break; // 想定外の命令が来た時.unreachable なはず default: error("oops"); } }
若干長いですが,それぞれの命令の処理はシンプルなので,それに対応する処理もシンプルです.生成されるコード例もコメントの中に書いてみました.
今回は簡単のため,入力は getchar(),出力は :echon で行うことにしました.これにより,標準入力は Vim 内での getchar() での読み込み,出力はメッセージ領域への表示とすることができます.getchar() は Nul 文字を扱えなかったり,:echon は不可視文字を表示できなかったりで不完全になってしまいますが,それは良いとします.
全体のコード生成
最後に今まで定義してきた関数を使って EIR を Vim script に変換する関数 target_viml() を定義します.これが elc.c 内で呼び出されます.
出力される Vim script プログラムはプログラムカウンタの値によっていくつかのチャンクに分けられます.それぞれのチャンクを Func0, Func1, ... と定義して,プログラムカウンタの値によってそれらの関数を呼び分けるようになっています.(例えば,0 <= pc && pc < 512 の間の処理は Func0 など)また,プログラムカウンタの1回のインクリメントでベーシックブロック1つ分の命令が実行されます.
よって,生成されるコードのレイアウトは次のようになります.
" (1) " レジスタやメモリの初期化 let s:a = 0 let s:b = 0 let s:c = 0 " ... let s:mem = repeat([0], 16777216) " ... " (2) function! Func0() " pc が 0〜511 の間の処理 while 0 <= s:pc && s:pc < 512 if 0 elseif s:pc == 1 " PC = 1 に対応するベーシックブロックの命令群を実行 elseif s:pc == 2 " PC = 2 に対応するベーシックブロックの命令群を実行 elseif ... " ... endif " プログラムカウンタを1増やして次の命令を実行する let s:pc += 1 endwhile endfunction function! Func1() " pc が 512〜1023 の間の処理 endfunction " ... Func2, Func3, ... とプログラムが続く限り続く " (3) " プログラムカウンタの値に対応するチャンクの関数を呼び出す " EXIT 命令が来る(=関数が 1 を返す)まで while ループで実行 " しつづける while 1 if 0 elseif s:pc < 512 if Func0() | break | endif elseif s:pc < 1023 " ... " elseif ... endif endwhile
上記のような構造のコードを生成しているのが下記のコードです.
// Func0 などの関数の開始部分のコードを生成する // プログラムカウンタの値が一定のうちは実行し,自分が実行すべき範囲を抜けたときに // while ループを抜けて関数を終了する. // CHUNKED_FUNC_SIZE が実行するプログラムカウンタの幅 (512) static void viml_emit_func_prologue(int func_id) { emit_line(""); emit_line("function! Func%d()", func_id); inc_indent(); emit_line("while %d <= s:pc && s:pc < %d", func_id * CHUNKED_FUNC_SIZE, (func_id + 1) * CHUNKED_FUNC_SIZE); inc_indent(); // elseif 決め打ちでコード生成できるように if 0 で始める emit_line("if 0"); inc_indent(); } // Func0 などの関数の終了部分のコードを生成する static void viml_emit_func_epilogue(void) { dec_indent(); emit_line("endif"); emit_line("let s:pc += 1"); dec_indent(); emit_line("endwhile"); dec_indent(); emit_line("endfunction"); } // 各プログラムカウンタごとに分岐する処理 // Vim script では elseif s:pc == {値} で分岐する static void viml_emit_pc_change(int pc) { emit_line(""); dec_indent(); emit_line("elseif s:pc == %d", pc); inc_indent(); } // エントリポイント void target_viml(Module* module) { // 初期化処理のコードを生成.上記(1) init_state_viml(module->data); emit_line(""); // emit_chunked_main_loop() は Func0, Func1, ... の定義を生成する関数.上記(2) // 上で定義したいくつかの関数を渡すと各チャンクを実行する関数のコードを生成してくれる int num_funcs = emit_chunked_main_loop(module->text, viml_emit_func_prologue, viml_emit_func_epilogue, viml_emit_pc_change, viml_emit_inst); // プログラムの実行部分のコード生成.上記 (3) emit_line(""); emit_line("while 1"); inc_indent(); emit_line("if 0"); for (int i = 0; i < num_funcs; i++) { emit_line("elseif s:pc < %d", (i + 1) * CHUNKED_FUNC_SIZE); inc_indent(); emit_line("if Func%d() | break | endif", i); dec_indent(); } emit_line("endif"); dec_indent(); emit_line("endwhile"); }
これで実装は一通り終わりました.C コード → Vim script のコンパイラが C で実装できたことになります.コード全体は長いので Gist に置きました.
早速 make でビルドしてから遊んでみます.テストは入力に NUL 文字を含むものがあったりするのと,入力の最後に改行を入れないと入力されないので多分通らないですが,気にしないことにします(ちゃんとスキップするように指定すれば良いですが).
まずは,コンパイルする C のコードを用意します.
int putchar(int x); int main() { const char* p = "Hello, world!\n"; for (; *p; p++) putchar(*p); return 0; }
まずは C → eir にコンパイルしてみます.コンパイルされた 8cc は ./out/8cc に入っているので,
$ ./out/8cc -S -I. -Ilibc -o hello.eir hello.c
とすると EIR 形式に変換されたコードが生成されます.
.text
main:
mov D, SP
add D, -1
store BP, D
mov SP, D
mov BP, SP
sub SP, 1
.file 1 "hello.c"
.loc 1 7 0
# ...
次に,これをバックエンドに食わせます.バックエンドである elc は ./out/elc に入っているので,
$ ./out/elc -viml hello.eir > hello.vim
とすると,hello.c を Vim script にコンパイルしたものが得られます.
最後に hello.vim を Vim で開き,:source コマンドで読み込みます.% は今開いているバッファのファイルパスを表しています.
:source %
すると,このように Hello, world! の文字列がメッセージ領域に表示されました.ちゃんと動いているようです.

これで C → Vim script のコンパイラの C 実装が得られました.それでは最後に C → Vim script のコンパイラの Vim script 実装を得ます.
上でも書いたように,8cc はセルフホスト済みのコンパイラです.つまり,自分で自分自身のコードをコンパイルできます.それを利用して,今回作成した C 実装を自分自身でコンパイルします.
$ ./out/8cc -S -I. -Ilibc -o 8cc.eir ./out/8cc.c $ ./out/elc -viml 8cc.eir > 8cc.vim $ ./out/8cc -S -I. -Ilibc -o elc.eir ./out/elc.c $ ./out/elc -viml elc.eir > elc.vim
ELVM のフロントエンド部分 8cc.vim とバックエンド部分 elc.vim が手に入りました.後は,上記の hello.vim と同じ要領で Vim 内からこれらのコードを読み込んで順番に変換していけば C → Vim のコンパイルができ,生成物を :source すれば C の実行結果が得られます.つまり,ピュア Vim script で C のコードを実行できるようになったわけです.やりました!
ちなみに実際に ELVM にプルリクエストを出した Vim script バックエンドは任意の入力・出力が Vim で行えるように工夫されており,8cc.vim ではさらにそれを Vim プラグインとして扱いやすいように改造したものを bundle しています.ですが,基本的にやっていることは上記と同じです.
また,同様にすることで,Vim script 以外の言語でもその言語で実装された C コンパイラが生成できます.
実行速度
実際に試してみると,上記の実行はめちゃくちゃ遅いです.どのくらい遅いかというと,MacBook Pro 2015 Late (core i5) で Hello world プログラムの実行に 824 秒(フロントエンド 430 秒 + バックエンド 396 秒)かかります.やばいですね…
なので,使える(?)ようにするには実行速度を改善する必要がありそうです.
Vim にはプロファイラ機能があり,Vim script の関数や行ごとの実行時間を簡単に調べることができます.(詳しくは :help profile)
ざっと調べた感じでは次のようなことが分かっています
- ホットスポットは特に無く,全体的にまんべんなく遅い(要は Vim script 実行が遅い)
- 開始時の
repeat([0], 16777216)は3秒ぐらいかかっていて,Vim 本体の実装を見た感じだとリストの後ろにどんどん継ぎ足していく感じなので遅いっぽい?しかし改善しても焼け石に水… - メモリをリストで取ると,インデックスアクセスが遅いので,辞書型を使う.これだとベンチマークで大体 1.2 倍ぐらい速くなる.
上記 3. とかはすぐできそうですが,1. については vimlparser でいったんパースして最適化パスを通してから書き出すみたいなことをやってコード量を減らさないとキツそうです.今回は時間がなくてそこまでできませんでしたが,楽しそうなのでどこかで時間を見つけてやってみて最適化編を書いてみたいです.Emacs Lisp バックエンドもあって,Vim script 実装は elisp 実装に比べるとかなり遅いっぽいです.頑張りたい…
なにがうれしいのか
8cc.vim が Reddit で少し話題になった とき,一番最初についたコメントは「Why?」でした.
8cc.vim には,Cコンパイラが無くネットワークにも接続されていないような過酷な環境でも編集に使う Vim さえあれば C を実行できるという素晴らしい意義がある…というわけでは特になく,単に面白そうだったのでやってみたという感じです.こういう特に役に立たないものをつくっている時は,だいたいつくる過程が楽しくてやっています.どちらかというとゲームとかをやっている感覚に近くて,クリアする過程を楽しんでクリアした結果自体はどうでも良い,という感じです.実際,ハーバードアーキテクチャな実装とか教科書ぐらいでしか見たことがなかったので,なかなか楽しめました.
また,すでにちゃんと書かれたテストやツールがあり,バックエンドを追加するという本質的な(楽しい)部分以外でほとんど作業しなくて良かったのも大きかったと思います.自分がやってる他のアプリプロジェクトとかでもこうありたいなぁと思ったりしました.
ELVM にはすでにいくつかの難解言語バックエンドがあり,unlambda バックエンドや C++ 定数式を利用したコンパイル時バックエンドといった面白いものがプルリクエストで追加されています.皆さんも得意な/好きな/難解な言語で実装された C コンパイラを生成してみると,楽しいと思うのでオススメです.
関連エントリ
Unlambda 実装についてのエントリが同日に書かれていました.Unlambda は SKI コンビネータを用いた難解言語で ELVM バックエンドの実相難度は Vim script より遥かに高いです.すごい…!
また,TeX や C++ 定数式での実装についても記事が書かれていました.
同じ対象を別言語で実装している人がいると,こういうのを読めるという楽しみがありますね.
*1:便利…?
GitHub Flavored Markdown をもっと Vim でハイライトする vim-gfm-syntax つくった
Vim にはデフォルトで Markdown のドキュメントをハイライトするためのファイルが同梱されています.基本的にはこれで満足なのですが,僕が書くのはほぼ GitHub Flavored Markdown(GFM: GitHub で使える拡張された Markdown 記法)なので,一部ハイライトされない構文があります.
そこで,既存のハイライトに GFM 向けのハイライトを追加する vim-gfm-syntax という Vim プラグインをつくりました.インストールは一般的な他のプラグインと同じです.ハイライトを追加するだけなので,設定済みの markdown ファイルタイプの設定を壊すことは無いはずです.
| 入れる前 | 入れた後 |
|---|---|
 |
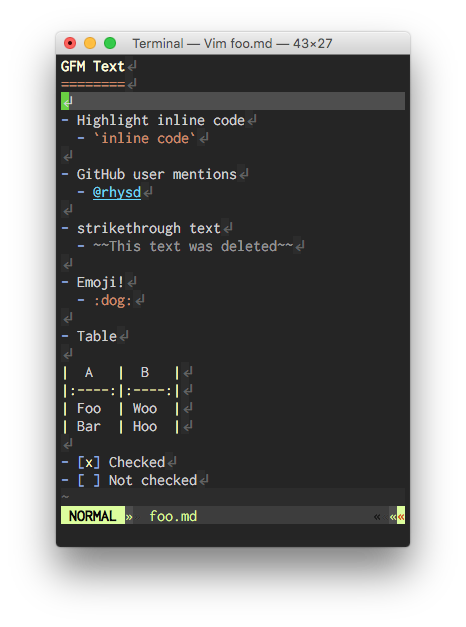 |
このプラグインを入れると,デフォルトで markdown ファイルタイプのファイルを読んだ時に次のハイライトが追加されます.
- テーブル記法
- 絵文字記法 (e.g.
:dog:) - タスクリスト記法 (e.g.
- [x]) - 打ち消し線記法 (e.g.
~~取り消された文~~) - issue 番号記法 (e.g.
#123) - メンション記法 (e.g.
@rhysd) - インラインコード記法(コードブロック記法を含まない) (e.g.
code)
1〜6 は GFM 特有の記法で,デフォルトでは全くハイライトされないものです.7 を入れた理由は後の方で説明します.
デフォルトですべてのハイライトが常に有効になるようになっていますが,挙動をある程度制御できるようにいくつかのカスタマイズ方法を提供しています.
ほしい構文だけハイライトする
vim-gfm-syntax では上記のうちほしいものだけをハイライトできます. g:gfm_syntax_highlight_ で始まる変数でそれぞれの構文をハイライトするかどうかを決められます.(詳細は README をご覧ください)
特定の場合だけハイライトしてほしい
commonmark などの普通の(?) Markdown 記法を使う時は上記ハイライトをしてほしくない場合もあると思います.なので,特定のファイルタイプだけハイライトを追加するようにカスタマイズできるようになっています.例えば下記は markdown.gfm というサブファイルタイプをつくって,特定のファイルでのみ追加のファイルタイプを有効にするようにしています.markdown.gfm は markdown のサブファイルタイプなので markdown の設定も読み込まれます.
" デフォルトでハイライトしない let g:gfm_syntax_enable = 0 " filetype が 'markdown.gfm' のときだけハイライトを追加する let g:gfm_syntax_enable_filetypes = ['markdown.gfm'] " 'README.md' というファイルを編集する時は filetype を markdown.gfm にして GFM ハイライトを有効にする autocmd BufRead,BufNew,BufNewFile README.md setlocal ft=markdown.gfm
ハイライトの色を変えたい
ハイライトの色合いは使っているカラースキームで決まるため,このプラグインが設定しているデフォルトの色合いがベストとは限りません.そのため,ColorScheme autocmd イベントでハイライト色を上書きできるようになっています.
例えば下記は githubFlavoredMarkdownCode(インラインコード記法のハイライト定義)を CursorLine と同じになるように上書きしています.
autocmd ColorScheme * highlight link githubFlavoredMarkdownCode CursorLine
CursorLine は一例で,:hi コマンドでハイライト一覧を見て選ぶことができます.また,githubFlavoredMarkdown で始まる各種コードハイライト名は コード を直接参照してください.
コードブロックのシンタックスハイライト
標準の Markdown ハイライトが対応済みです.
let g:markdown_fenced_languages = ['cpp', 'ruby', 'json']
のようにすると C++,Ruby,JSON のコードブロックがそれぞれの言語の構文でハイライトされます.ただし,数を増やしすぎると Markdown ハイライトの読み込みが重くなってしまうので注意です.
インラインコードのハイライト
Vim の標準の構文ハイライトでは,コード記法は ` のみがハイライトされ,その中身が表示されません.そのため,インラインコードを多用するライブラリのドキュメントではインラインコードの範囲が分かりにくくなります.実は標準のハイライトではデフォルトのハイライトが設定されていないだけで下記のように markdownCode ハイライトを定義してやると色をつけてくれます.
autocmd ColorScheme * highlight link markdownCode Constant
にも関わらず冒頭の 7. を追加したのは,markdownCode だと ``` で始まるコードブロックも一緒にハイライトされてしまうためです.ここは好みですが,文中のインラインコードだけハイライトしてほしい場合はこれではできないため,今回は githubFlavoredMarkdownCode を新たに追加しました.
Well-tested
themis.vim を使って各種ハイライトやカスタマイズ機能をテストしています.また,Travis CI も利用しています.
ErgoDox EZ を使い始めて1ヶ月ぐらい経った
タイムラインで購入している人がちらほらいて,評判も良好みたいなので ErgoDox EZ というキーボードを試しに買ってみることにしました.購入したのは無刻印+アームレスト付きの赤軸です.
 (画像は公式サイトから)
(画像は公式サイトから)
とりあえず購入して1ヶ月経ち,そこそこ慣れてきて違和感なく打てるようになってきたので,この辺りで備忘録がてらまとめてみることにしました.
購入
他の人のブログを読んでいると手続きして2週間以上かかったりしていたので,お盆明けぐらいに届けば良いかなーという気持ちで7月22日に購入手続きをしました.しかし実際は台湾からの発送で1週間で届きました.8月頭に1週間サンフランシスコ出張があったので受け取れなかったら返送されてしまうとヒヤヒヤしましたが何とか直前に受け取れました.
セットアップ
出張前にとりあえずセットアップだけしました.と言っても箱から出して高さを調節して設置してみて,ファームウェアのビルドができることを確認しただけです.
この記事がとても参考になりました.コマンドラインから make 一発でビルドしてファームをキーボードのマイコンに焼きこむところまで出来るのでかなり楽です.
ErgoDox のキーボードファームウェアはオープンソースで開発されているので,リポジトリ を手元に clone してきて必要なクロスビルド用のライブラリを Homebrew で入れるだけで OK です.
他の人のブログ記事を読んでいると qmk_firmware リポジトリを fork して自分の設定を足している人が多いですが,僕は設定ファイルは極力 dotfiles に置きたいので,clone してきたリポジトリ内に ergodox/keymaps/rhysd をつくってその中に dotfiles からシンボリックリンクを張りました.この辺は何でも良さそうですが.
なお,デフォルトだと PC がスリープ状態になったときに LED が光って邪魔だったのですが,Makefile 読んでみるとビルド時に指定することでオフにできました.
$ make teensy KEYMAP=rhysd SLEEP_LED_ENABLE=no
キー配置を考える
キーマップいじくるのは好きなのでお盆休みあたりに少し色々試してみました.キーマップは C 言語のプリプロセッサマクロで簡単に定義できます.最終的なキー配置はこんな感じ.(設定ファイル)
- 左側
,---------------------------------------------------.
| ESC | 1 | 2 | 3 | 4 | 5 | 6 |
|--------+------+------+------+-------+-------------|
| Tab | Q | W | E | R | T | { |
|--------+------+------+------+-------+------| |
| LCtrl | A | S | D | F | G |------|
|--------+------+------+------+-------+------| } |
| LShift | Z | X | C | V | B | |
`--------+------+------+------+-------+-------------'
|C-Left| | | LAlt |LG/Eisu|
`-----------------------------------'
,--------------.
|LGuiEnt| |
,------|-------|------|
| | | Home |
|Ctrl/ |TapL1/ |------|
|Space |Tab | End |
`---------------------'
- 右側
,----------------------------------------------------.
| | 7 | 8 | 9 | 0 | - | = |
|------+------+-------+------+------+------+---------|
| _ | Y | U | I | O | P | \ |
| |------+-------+------+------+------+---------|
|------| H | J | K | L | ; | '" |
| = |------+-------+------+------+------+---------|
| | N | M | , | . | / | ` |
`-------------+-------+------+------+------+---------'
|RG/Kana| RAlt | [ | ] |C-Right|
`------------------------------------'
,---------------.
|AltTab|LGuiSpc |
|------+--------+--------.
| PgUp | | |
|------|BackSpc |RShift/ |
| PgDn | |Enter |
`------------------------'
基本的には英字配列からあまり外れないように
慣れるのが大変そうなので,基本的な配置はなるべく US からあまり外れないようにしました.例えば左端の Ctrl や Shift などのキーは残す,以前のキーボードで左手で押していた 6 キーは引き続き左手で押せるように移動する(デフォルトでは右手で押すようになってた)など.
ただし,ErgoDox のキーボードの列数は HHK のそれよりも少ないため,どうしても足りなくなります(特に右端の記号列).これはどうしようもないので,あぶれた [ と ] は最下段へ… これはちょっと押しにくいのでもう少し考えたいところです.今までのキーボードは小指の守備範囲が広くて,記号を多用するプログラミングでは結構つらかったので,それが解消されるならお釣りがくるかなという感じです.
単押し,複数押し
ErgoDox ではモディファイアキー(他のキーと一緒に押す Ctrl などのキー)の挙動をかなり細かく指定することができます.例えばキー単体を押した時は半角スペースを入力し,他のキーと一緒に押した時は Ctrl として働くといったことができます.また,Ctrl を押した次のキー入力が Ctrl と一緒に押した扱いになるワンショットなどの挙動も指定できます.
親指にたくさんキーを割り当てられるので,ここはしっかり活用したくて特に左右に2つずつある大きい親指キーには単押しと複数押しにそれぞれ割り当てています.
,---------------. ,---------------.
|LGuiEnt|LGuiSpc| |AltTab|LGuiSpc |
,------|-------|-------| |------+--------+--------.
| | | Home | | PgUp | | |
|Ctrl/ |TapL1/ |-------| |------|BackSpc |RShift/ |
|Space |Tab | End | | PgDn | |Enter |
`----------------------' `------------------------'
- 左手親指
- 単押しはスペースキー,他のキーと同時押しで Ctrl キー
- 単押しはタブキー,他のキーと同時押しでレイヤー2(後述)のキー配置
- 右手親指
- 単押しは Enter キー,他のキーと同時押しで Shift キー
- バックスペースキー
これだとキー長押しのキーリピートができなくなるのではと思われるかもしれませんが,同じキー2連打以降の長押しはキーリピートとして扱われる仕様のため問題ありませんでした.
ちなみに親指向けにはさらにキーが配置できるようになっていますが,一番外側の縦3つのキーはホームポジションから指が届かないのでほぼ使ってません.この辺は外国人サイズなのかも.さらに Vim 的には Esc キーが親指のほうが良いかなとも思ったのですが,普段 jj で挿入モードから抜けるようにしているのと,Vim 以外ではほとんど使わないので Esc キーは普段の位置に収まりました.
英数キー,かなキー
僕は IME の状態を覚えておかないといけない 半角/全角 的なトグルキーが嫌で Mac の JP 配列のような英数キーやかなキーを使っています.HHK ではその挙動にするために Karabinar のお世話になっていたのですが,今回はファームウェアのキーマップ書き換えで出来そうなのでやってみました.
最初調べて出てきた情報によるとパッチを当てないとだめとのことでしたが,該当箇所を確認したところ既に修正された跡がありました.issue を漁ってみると下記を見つけました🙏.
Can't use KC_LANG1 & KC_LANG2 key
どうやら既に LANG1 がかなキー, LANG2 が英数キーとして使えるようなのでそのまま使ってみるとちゃんと動きました.Karabinar で設定していたのと同じように,単押しで IM 切り替え,他のキーと同時押しで Cmd キーになるようにしました.
Alfred や iTerm2 に1キーでアクセス
僕は普段ターミナルで作業するので,Cmd+Enter で iTerm2 を全画面トグルで使えるようにしています.また,Alfred もよく使うので,Cmd+Space にホットキーを設定しています.
ErgoDox ではこれらのホットキーを1ボタンに割り当てています.左親指キーの LGuiEnt というのがターミナルのトグルで,右親指キーの LGuiSpc というのが Alfred のホットキーです.頻繁に使うアプリのホットキーが1キーになることで思ったより楽になりました.
また,左右のワークスペースへの切り替えも最下段の一番端のキーのみで行えるようにしました(C-Left と C-Right がそれです).元々 Karabinar に頼って Ctrl + 左Cmd/右Cmd で切り替えというかなり変わったキー配置をしていたのですが,それが1キーで出来るようになりました.
キー配置レイヤー
ErgoDox ではキー配置にレイヤーを持たせることができ,Vim のモードのように複数のキー配置を切り替えることができます.レイヤーは3つ設定できます(デフォルトのレイヤーが L0 なので残りの L1 と L2).各レイヤーには Vim のようにキー入力で遷移したり,キーを押している間だけレイヤーを変えたり,キーを押した次の入力だけレイヤーを切り替える(ワンショット)といった好きな方法でアクセスできます.
僕はレイヤー3つは使いこなせる感じがしなかったので L1 だけ使い,F1〜F12 や方向キー&Home・Endキー,列が足りなくて再現できなかった右端の記号列のキー配置を設定したりしてますが,F1〜F12 と方向キーぐらいしかちゃんと使えていません.もっとレイヤーを使いこなしたい…
ErgoDox のキー配置(物理)について
ErgoDox は今まで僕が使ってきたキーボードとは違い,縦にまっすぐにキーが配置されています.そのため,以前のキーボードに慣れている指では最初誤入力が多発しました(特に C と V とか).これについてはキーボードに対する腕の向きが大事でした.一般的なキーボードは,キーボードに対して腕がハの字になるように設計されていると思います.それに対して ErgoDox では腕がキーボードに対して垂直になるように意識的に直してやる必要がありました.腕の向きを直すと大分誤爆が減りました.
また,ErgoDox に慣れると今までのキーボードが打てなくなるのではという懸念がありました.しかし今までは HappyHacking (US配列) を使っていて,職場では静音の Realforce (JP配列) を使っているので,新しい配列が加わったという感覚で,今までのキーボードが打てなくなるといったことは無さそうです.
打鍵感と音と振動
これらについては残念ながら以前の HHK のほうが遥かに良かったです.
打鍵感は HHK のほうがキーの押し込みがスムーズで押し心地が良いです.さすがに静電容量無接点方式にはメカニカルでは敵わないのかなという印象でした.
また,僕はキーの押下圧が強くて,HHK の時は特に気にならなかったのですが,ErgoDox では入力の振動が机に伝わってしまってモニターが少し揺れたりすることがあります.この辺りは良い机を買ったりすれば少しマシになるのかもしれませんが…
あと,音もちょっと気になりました.静音でない HHK Pro2 よりも大きいです.自宅では特に気になりませんが,職場でこの音は僕的にはちょっと…という感じです.
肩凝り
僕は昔から結構肩凝りがひどいのですが,それはかなりマシになりました.肩が開いて姿勢も良くなるので,そのおかげだと思います.日中ずっとキー入力していても肩がつらくなってきて中断といったことはほぼなくなりました.
まとめ
今の時点でもう ErgoDox のみでコードを書いたりツイートを書いたりしていて,特に困っていないです.前述のとおり肩凝りが解消されたのと,かなり小指の負担が減ったように思います.あと,キー配置やキーの挙動の自由度がかなり高いので,新しいキー設定を思いついたら即試せて今後も楽しめそうです.
僕自身はキーボードを組み立てる技術が無いので壊れた場合のサポートとかが少し不安ですが,その時は HHK にフォールバックして考えます.新しいおもちゃが手に入ったというのと,肩凝り解消などの実益で,僕にとってはなかなか良い買い物でした.