Small String Optimization で Rust ライブラリ ratatui を最適化した話
最近 ratatui という crate に Small String Optimization を利用した最適化を入れたので,その話を書きます.
目次
- Small String Optimization (SSO) とは(SSO を既に知っている人は読み飛ばして大丈夫です)
- Rust で SSO を適用した文字列型を提供する crate 比較
- SSO を利用して ratatui のメモリ効率と実行効率を最適化した話
- compact_str crate の実装の最適化の話
- インラインストレージに24バイト全てを使える理由
- 隙間最適化のための工夫
説明を簡潔にするため,特に断りが無い場合 64bit アーキテクチャを前提とします.
Small String Optimization (SSO) とは
Rust の可変長文字列型 String は文字列バッファへのポインタ,文字列の長さ,バッファのキャパシティの3つのフィールド(8 + 8 + 8 = 24バイト)から成っており,文字列はヒープ上に確保された文字列バッファに置かれます.
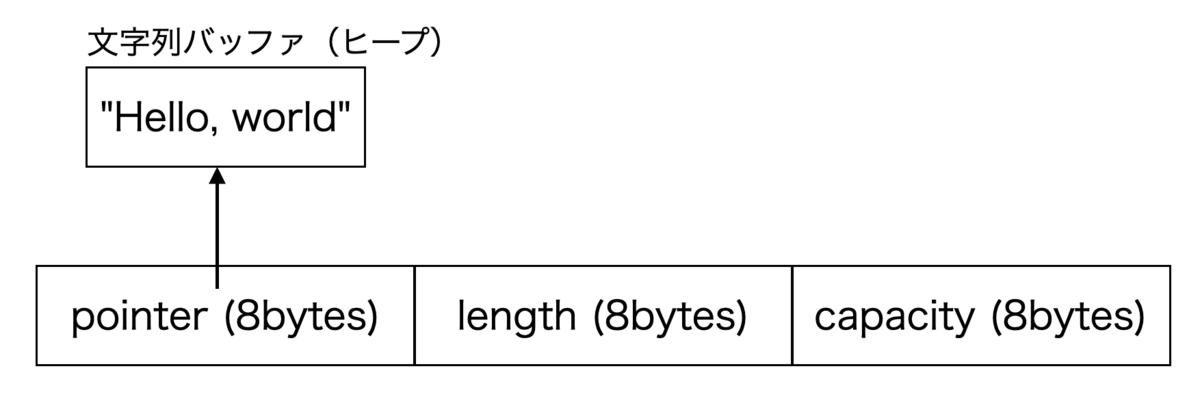
文字列が十分に短い場合,わざわざヒープに確保しなくても24バイトの構造体の中に直に(インラインに)文字列を置けば良いというのが Small String Optimization (SSO) の基本的なアイデアです.

上記の図は典型的な SSO の実装例です.下記のように,文字列長が23バイトまでとそれ以降で構造を使い分けます.
- 文字列長が23バイトよりも長いとき → 標準の
Stringのように文字列をヒープ上のバッファに置く.ポインタを構造体の一番最後のフィールドに置く.ポインタの最下位ビットは常に 0 なので,構造体の最後のバイトの最下位ビットをフラグとし 0 なら文字列をヒープに保存していることを表すことにする. - 文字列長が23バイトまで → 文字列を構造体の中にインラインに置く.最後の1バイトを除く構造体の頭から23バイトが利用可能.最後の1バイトは文字列長とフラグを保存するのに使う,最下位ビットはフラグとし 1 ならインラインに文字列を保存していることを表すことにする.残りの7ビットに文字列の長さを保存する(高々23文字なので過剰)
この最適化には下記のような利点があります.
- 文字列が短いうちはメモリ使用量が少なくて済みます.23バイトの文字列を表すのに,標準の
Stringだと少なくとも47バイトかかりますが,SSO を利用した文字列型では24バイトしかかかりません - 文字列が短いうちはヒープアロケーションを避けられる分速いです.また,構造体内に文字列を直接置くので,キャッシュの局所性も上げることができます
- 標準の
String型と構造体のサイズが変わりません(24バイト)
一方で下記のような欠点もあります.
- 文字列を構造体にインラインで置いているのかヒープに置いているのかで分岐が必要になる
- 標準の文字列型をサードパーティのライブラリもしくは自前の実装に置き換える必要がある
文字列をヒープに置いている場合は標準の String と構造が同じなので,分岐の分のオーバーヘッドがかかる分だけ不利になります.プログラムのロジック的に文字列がほとんどの場合インラインに置けるほど短いことが分かっている時に効果的です.
ちなみに C++ 標準の std::string の実装では SSO が利用されているため,C++ で std::string を使うと自動的に SSO の恩恵を受けることになります.
Rust で SSO を利用できる crate
Rust には SSO を利用した独自の文字列型を提供するサードパーティ製の crate が複数あります.下記は今回考慮した crate のリストです
- smartstring : 比較的素朴な実装の SSO 文字列型を提供
- compact_str : かなり最適化された実装の SSO 文字列型を提供.メンテ・開発が活発
- smol_str : rust-analyzer で使われている文字列型.コピーオンライト(実際に文字列が変更されるまで文字列バッファのコピーを行わない)な実装になっており,文字列のクローンが O(1) でできる.一般的な用途には ecow のほうが良いと作者自身がコメントしていた
- ecow : 参照カウントでコピーオンライトな実装の文字列型を提供.文字列のクローンが O(1) ででき,サイズが 2 words(16バイト)しかない.typst の内部実装で使われている.名前の由来は eco + cow = ecow ?
各 crate が提供する文字列型の機能比較を下記の表にまとめました.
| 型のサイズ | インライン文字列の最大サイズ | クローンの効率 | |
|---|---|---|---|
標準 String |
24バイト | - | O(n) |
| smartstring | 24バイト | 23バイト | O(n) |
| compact_str | 24バイト | 24バイト | O(n) |
| smol_str | 24バイト | 23バイト | O(1) |
| ecow | 16バイト | 15バイト | O(1) |
これらの crate 全てに共通する点として,標準の String を置き換えて簡単に使えるよう,標準の String の API と互換性を持たせています.このおかげで,最小限の労力でこれらの crate を導入することができます.
今回のケースではコピーオンライトな実装は不要だったので,compact_str を使うことにしました.インラインに文字列を置く際に24バイトすべてを使うことができる理由はcompact_str の実装の最適化の話の章で説明するので気になる方は読んでみてください.
ecow は非常に凝った実装ですが,アトミックな参照カウントの上下や参照カウントおよびキャパシティをヒープに保存する分のオーバーヘッドを考慮する必要があります.
前述の通り String との API の互換性により簡単に試せるので,実際に導入してパフォーマンスの変化を見るのが重要です.パフォーマンスが改善できない場合は構造が最もシンプルでサードパーティの依存を増やさない標準の String を使うのがベストです.
ratatui を最適化した話
ratatui とは
ratatui は Terminal User Interface (TUI) アプリを実装するためのライブラリで,GUI フレームワークのようにウィジェットを組み合わせることでターミナル上での UI を構築できます.C でいう ncurses が比較的近いかもしれません.以前は tui-rs というプロジェクトだったのですが,メンテが止まってしまったのでコミュニティベースで fork して ratatui という crate として開発が継続されています.僕も tui-textarea というテキストエディタ機能を提供するウィジェットを開発しています.
前章で説明した通り,今回は ratatui の内部構造を compact_str を使って最適化しました.
ratatui の内部構造の最適化
ratatui はターミナル上の1文字を Cell という単位で保持しています.
例えば下記のような UI を表示している時,
┌───┐ │abc│ └───┘
バッファは下記のような単純な構造で保持されています.
vec![ Cell("┌"), Cell("─"), Cell("─"), Cell("─"), Cell("┐"), Cell("│"), Cell("a"), Cell("b"), Cell("c"), Cell("│"), Cell("└"), Cell("─"), Cell("─"), Cell("─"), Cell("┘"), ]
ここでのポイントは「1文字」というのが Unicode の書記素クラスタ単位であるということです.書記素クラスタは👨👩👧👦絵文字が有名なように複数のコードポイントで成るので,Rust の char で保持することはできず,Cell は内部で1文字ごとに String で文字列を持ちます.
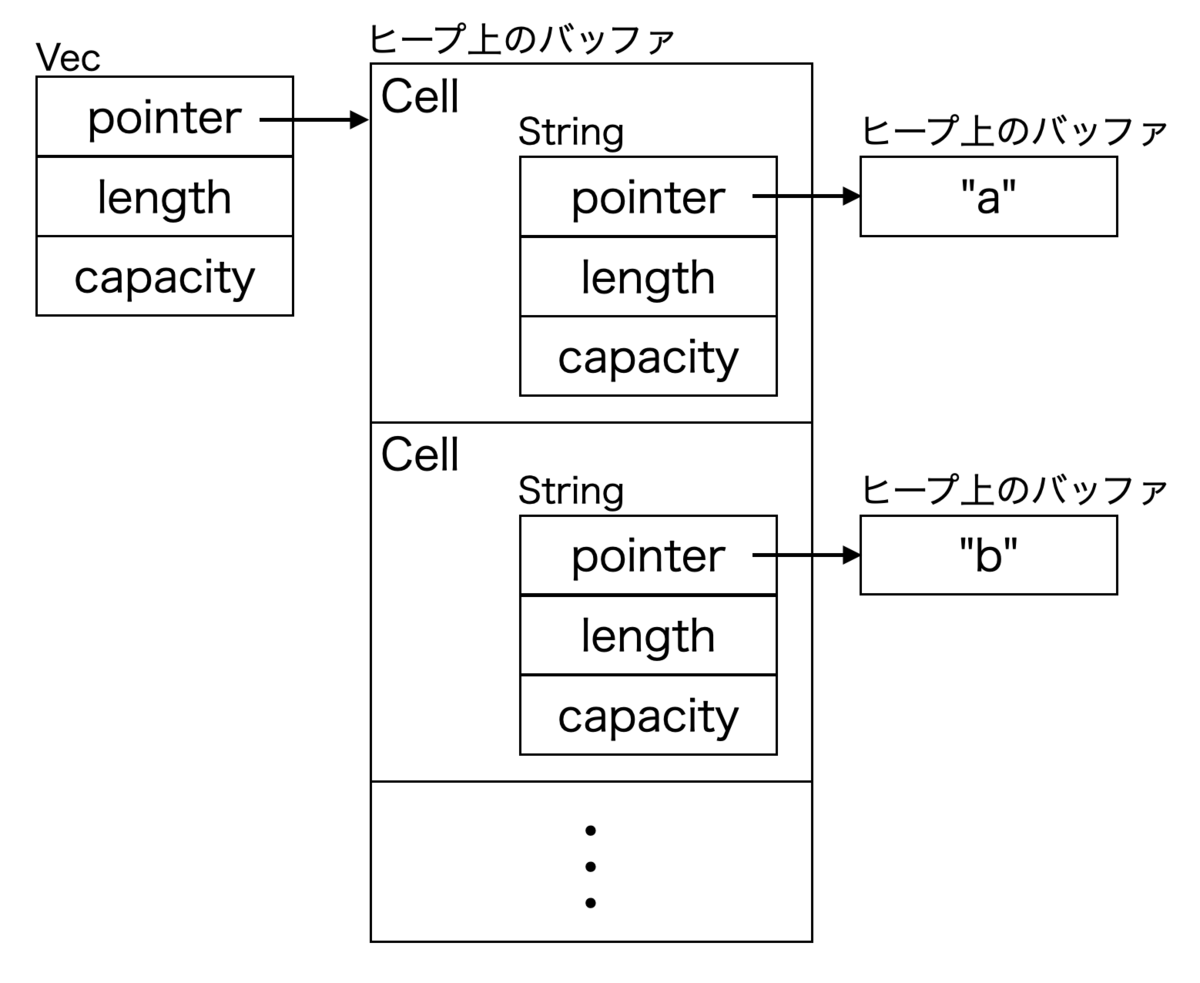
つまり,大量の Cell の1つごとに小さいヒープ割当が発生してしまいます.Cell が持つ文字列はほぼ全てのケースで24バイトに収まるので,これを SSO で最適化した文字列型を用いて最適化するのは妥当に見えます.下記のように文字列はすべて Vec の要素のバッファにインラインで保存できるはずです.
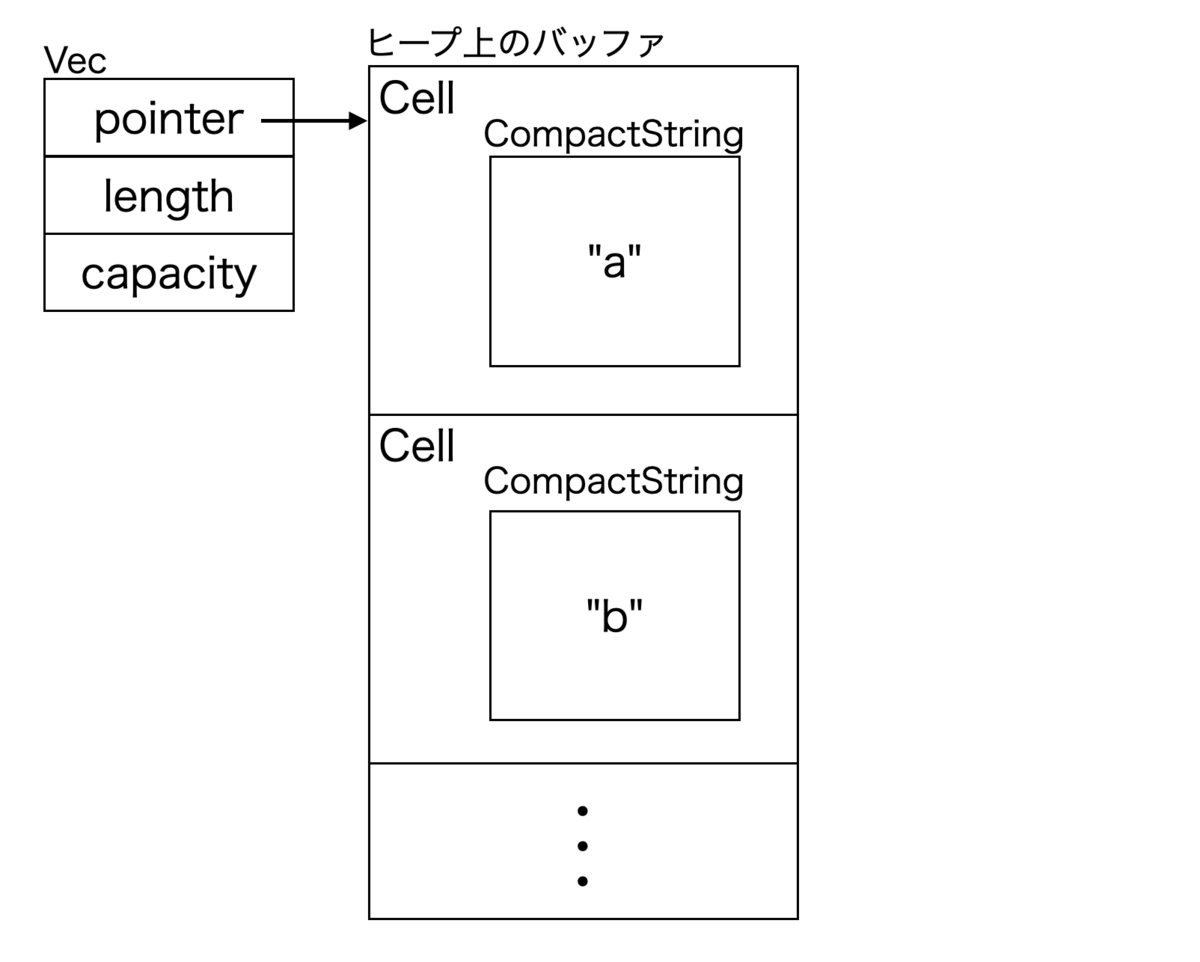
これにより下記のような改善が期待できます.
- ヒープ割り当てのサイズを減らせる(メモリ使用量改善)
- ヒープ割り当ての回数を減らせる(初期化時およびリサイズ時のパフォーマンス改善)
- メモリの局所性を上げられる(キャッシュ効率改善)
macOS でメモリ使用量を計測する方法
CPU プロファイラは結構色々選択肢があるのですが,メモリプロファイラは実はあまりメジャーな方法が無く検索しても情報が少なかったのでやり方を簡単に説明します.Linux はおそらく perf mem でメモリプロファイルが取れるのですが,VirtualBox 上の VM では PMU イベントが取れず利用できなかったので,別の方法を検討しました.
Xcode の Instruments をコマンドラインから利用します.まずは対象のバイナリをビルド
cargo build --example demo --release
次に xctrace コマンドによりインストルメンテーションを有効にしてバイナリを実行します.テンプレートには Allocations を使います.
xctrace record --template Allocations --launch -- ./target/release/examples/demo
注意点として,xctrace はプログラムの標準入出力を奪ってしまう問題があります.ratatui はターミナルのバックエンドを切り替える仕組みがあるので,標準入出力を使わないようにテスト用のバックエンドに実装を直接書き換えることで回避しました.
実行が完了するとカレントディレクトリにトレースファイルが生成されるので,後はそれを開けば Xcode 上で計測結果を解析することができます.
open Launch_demo_2023-10-28_21.18.03_AF4F797C.trace
最適化の効果の計測
ratatui の PR で実際に計測した結果を説明します.計測対象には demo example を利用しました.
メモリ使用量
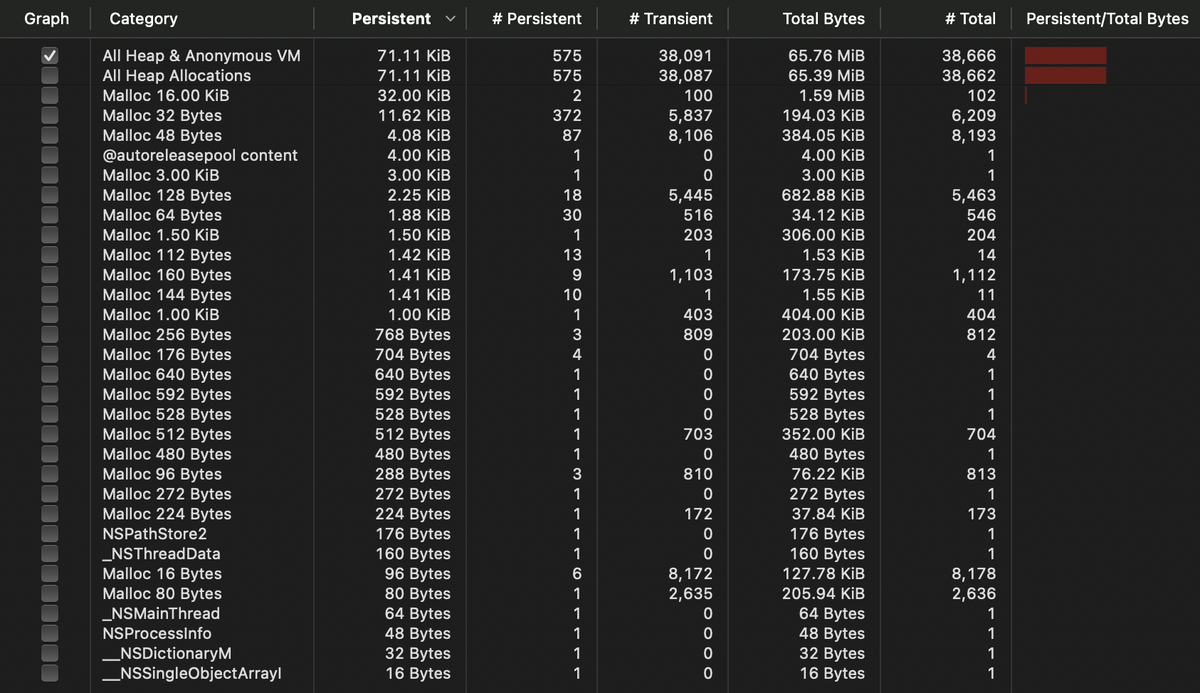
計測対象のアプリで 100 tick 分の描画中に発生したメモリアロケーションを計測しました.
狙い通り16バイト単位のアロケーションの回数が288895回から8178回に大幅に減り,結果として割り当てられたメモリのサイズも 4.41Mib から 127.78Kib へ約35分の1と大幅に減少しました.
main branch |
sso branch |
|
|---|---|---|
| Total bytes | 4.41MiB | 127.78KiB |
| # of allocs | 288895 | 8178 |
| Screenshot | 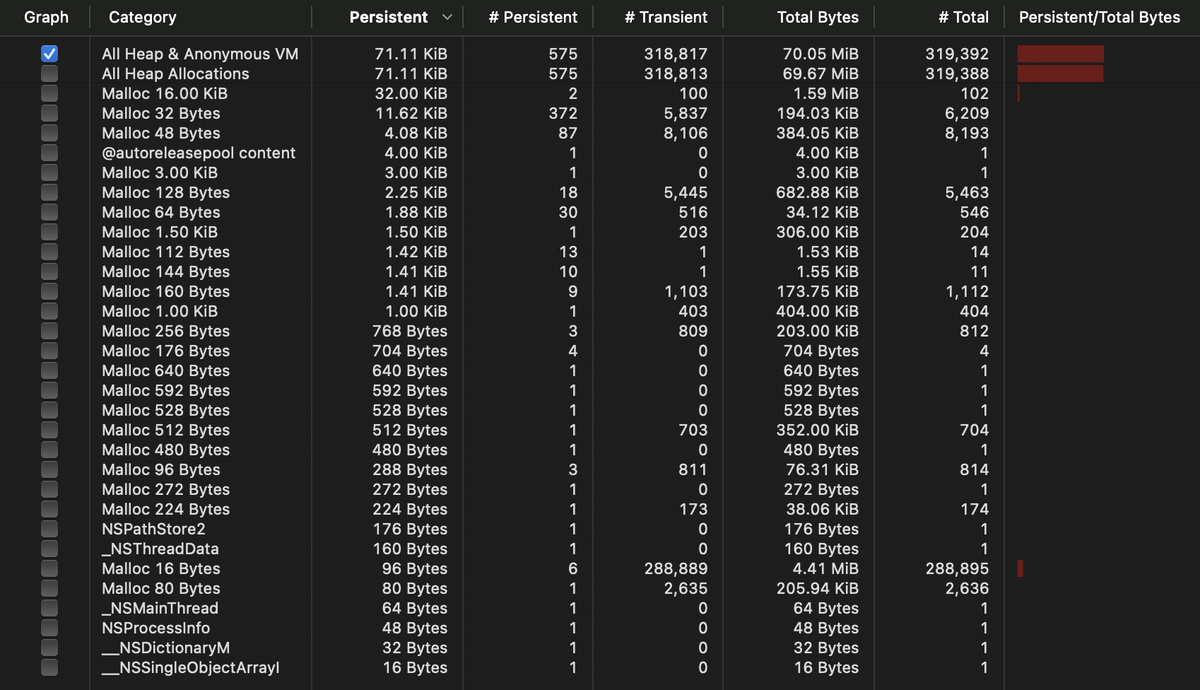 |
 |
CPU 実行効率
実行時間を hyperfine で計測しました.100 tick 分の描画にかかった時間と,初期化時のヒープ割り当て減少による改善を見たかったので最初の tick のみの描画にかかった時間の2通りを計測しました.demo_main が main ブランチをビルドしたバイナリで,demo_sso が今回改善を入れたブランチをビルドしたバイナリです.
100 tick 分の実行効率は 1.14 倍高速化しました.
$ hyperfine ./demo_main ./demo_sso
Benchmark 1: ./demo_main
Time (mean ± σ): 85.2 ms ± 2.5 ms [User: 81.8 ms, System: 2.1 ms]
Range (min … max): 82.2 ms … 94.9 ms 34 runs
Benchmark 2: ./demo_sso
Time (mean ± σ): 74.9 ms ± 0.6 ms [User: 72.2 ms, System: 1.5 ms]
Range (min … max): 73.3 ms … 76.8 ms 38 runs
Summary
./demo_sso ran
1.14 ± 0.03 times faster than ./demo_main
最初の tick のみだと 1.77 倍高速化しました.初期化時のヒープ割り当ての影響が大きいためだと思います.
$ hyperfine --shell=none ./demo_main ./demo_sso
Benchmark 1: ./demo_main
Time (mean ± σ): 8.8 ms ± 0.4 ms [User: 6.4 ms, System: 1.5 ms]
Range (min … max): 8.4 ms … 11.4 ms 316 runs
Benchmark 2: ./demo_sso
Time (mean ± σ): 5.0 ms ± 0.1 ms [User: 3.0 ms, System: 1.1 ms]
Range (min … max): 4.7 ms … 5.8 ms 581 runs
Summary
./demo_sso ran
1.77 ± 0.09 times faster than ./demo_main
compact_str の実装の最適化の話
ここでは compact_str crate が内部で行っている最適化のうちのいくつかについて説明します.これ以外にも分岐無し命令を利用した最適化など,吐かれる機械語を意識した細かい最適化がたくさん行われています.コードコメントがかなり丁寧に入っているので,そのあたりに興味がある人はぜひコードを読んでみてほしいです.
24バイト全てをインライン文字列に使う
Rust で SSO を利用できる crate の章で書いた通り,compact_str の提供する文字列型 CompactString は標準の String に合わせてサイズが24バイトになるように実装されています.一方で,構造体内にインラインに保存できる文字列のサイズも24バイトです.Small String Optimization (SSO) とは の章で書いた通り,SSO を素朴に実装すると,「今文字列をインラインに保存しているかどうか」を示すためのフラグ(と現在の文字列の長さ)に1バイト必要になり,構造体内にインラインに保存できる文字列のサイズは23バイトになるはずです.
CompactString は保存される文字列が UTF-8 でエンコードされていることを利用し,24バイト中の最後の1バイト内にフラグをエンコードしています.
文字列をインラインに保存している場合,24バイト目は必ず UTF-8 文字シーケンスの最後の1バイトになっています.UTF-8 文字シーケンスの最後の1バイトは0〜255の範囲全てを利用していません.なので,未使用の範囲をフラグに充てることができます.CompactString では,この未使用の範囲に文字列のサイズと「今文字列をインラインに保存しているかどうか」のフラグを割り当てています.(注: 実際は静的ストレージに保存された文字列(&'static str)をコピーせずに扱う最適化も絡んでもう少し複雑なのですが,ここでは説明を簡単にするためそれを省いています)
| 値の範囲 | 意味 |
|---|---|
| 0〜127 | ASCII 文字(1バイト) |
| 128〜191 | 非 ASCII 文字シーケンスの最後の1バイト |
| 192〜215 | 現在の文字列の長さ(24バイトなので0〜23) |
| 216 | 文字列がヒープに保存されていることを示すマーカー |
文字列の長さを表す範囲は16進数表現で 0x11000000 から 0x11010111 なので,左から1ビット目と2ビット目を落とせば文字列のサイズを取り出すことができます.
これにより,構造体24バイトのうち最後の1バイトを失うこと無く,下記のようにフラグと文字列のサイズと最大24バイトの文字列を同時に保持することができます.
最後の1バイトの値 b の条件 |
最後の1バイトの意味 | 文字列のサイズ |
|---|---|---|
b < 192 |
UTF-8 文字列の一部 | 24バイト |
192 <= b && b <= 215 |
文字列のサイズ | 0〜23バイト |
b >= 216 |
文字列はヒープに確保されているフラグ | 25バイト以上 |
一方で,ヒープに文字列を保存している場合(つまり文字列のサイズが24バイトを超える場合)は構造体内の最後のバイトを216以上とする必要があります.そのため,Small String Optimization (SSO) とは の章で書いたようなポインタの最下位ビットにフラグを持つということはできません.
CompactString ではヒープに文字列を保存している場合は構造体内の最後のフィールドであるキャパシティについて,下記のような実装になっています.
- 64bit OS の場合 → 文字列のキャパシティを1バイト削り7バイトとしている.これにより標準の
Stringのキャパシティ8バイトと比べて表せる文字列のサイズは72057594037927934バイト(約64ペタバイト)に減るが,そもそもそんな大きなサイズのメモリをプロセスが確保することはできないので問題なし - 32bit OS の場合 → 文字列のキャパシティを1バイト削り3バイトとすると文字列の最大サイズが16777214バイトとなり,現実的にこれを超えることができてしまう.なので,それを超える場合はキャパシティもヒープ上に置くようにする
32bit OS の場合の具体的な実装は話が細かすぎるのでここには書きませんが,気になる方は capacity.rs を読んでみてください.
隙間最適化を行えるようにする内部構造の工夫
隙間最適化(niche optimization)とは,隙間(ニッチ)をうまく埋めるようにフラグの有効値を配置することで構造体のサイズを抑える最適化です.(関連ドキュメント)
一番単純な具体例として Option<bool> を考えると,bool は1バイトの値で 0 が false,1 が true です.さらに Option は Some か None のどちらを取るかをフラグとして持つのでここでも1バイト必要になり,Option<bool> は素朴に考えるとサイズは2バイト必要になります.これを最適化して Some(false) を 0,Some(true) を 1,None を 2 とすることでサイズを1バイトに抑えることができます.
use std::mem::*; println!("{}", size_of::<Option<bool>>()); // => 1 let some_false: u8 = unsafe { transmute(Some(false)) }; let some_true: u8 = unsafe { transmute(Some(true)) }; let none: u8 = unsafe { transmute(<Option<bool>>::None) }; println!("{}", some_false); // => 0 println!("{}", some_true); // => 1 println!("{}", none); // => 2
標準でも NonNull や NonZeroU32 など,隙間最適化を意識した型が提供されています.また,enum を定義するとフラグに使わない無効な値の範囲が発生します.複雑な型では enum な型が深くネストしたりするため,この最適化が多重に行われ構造体のサイズを何バイトも節約することができます.メモリが比較的高価な組み込み環境などで使われることを Rust が想定していることや,Copy を実装するかどうかの基準がその構造体のサイズであることを考えると重要な最適化です.
前章でも書いたように CompactString は文字列を構造体にインラインに保存する場合,その24バイト全てを文字列に利用します.そのため下記のように単純に24バイトの配列として構造を定義してしまうとコンパイラは隙間最適化を行うことができません.
struct Repr([u8; 24]);
一方で,前章で書いたように CompactString の24バイト中最後の1バイトには未使用の範囲がまだ存在します.その範囲があることをコンパイラに伝えると隙間最適化ができるようになるはずです.
そのため,compact_str では CompactString の内部の構造体定義を下記のように工夫しています.(実際のコード)
struct Repr( // 最初の8バイト *const (), // 次の8バイト usize, // 最後の8バイト u32, u16, u8, LastByte, )
最後の LastByte は1バイトの enum 型で,定義は下記のようになっています.(実際のコード)
#[repr(u8)] enum LastByte { Ascii0 = 0, Ascii1 = 1, Ascii2 = 2, // ... Ascii127 = 127, MutiByte128 = 128, MutiByte129 = 129, MutiByte130 = 130, // ... MutiByte191 = 191, Len0 = 192, Len1 = 193, Len2 = 194, // ... Len23 = 215, Heap = 216, Static = 217, // 本記事では説明していない &'static str 向けの最適化のためのフラグ }
これにより,コンパイラはこの enum の定義を通じて「CompactString の24バイト目は218〜255が未使用の範囲(無効値)である」と認識することができ,この範囲を隙間最適化に利用できるようになります.結果として,例えば CompactString のサイズと Option<CompactString> のサイズが同じになります.
まとめ
本記事では下記の3点について書きました
- Small String Optimization (SSO) とは何か,Rust で SSO の恩恵を受けるにはどうすれば良いか
- 実際に ratatui という Rust ライブラリを SSO を用いて改善した結果
- 16バイトブロックのメモリ割り当て量が32分の1に減少
- 初期化時の実行効率が1.7倍速,平常時の描画の実行効率が1.1倍速
- SSO を利用した文字列型を提供する compact_str crate がどのように実装を工夫しているか
もし「小さい文字列を大量に割り当てる」というユースケースに心当たりがある場合はこの最適化の導入を検討してみてはどうでしょうか?優秀なサードパーティライブラリのおかげで容易に導入できるので,メモリプロファイラや CPU プロファイラを用いて複数のライブラリを比較検討することができます.