Small String Optimization で Rust ライブラリ ratatui を最適化した話
最近 ratatui という crate に Small String Optimization を利用した最適化を入れたので,その話を書きます.
目次
- Small String Optimization (SSO) とは(SSO を既に知っている人は読み飛ばして大丈夫です)
- Rust で SSO を適用した文字列型を提供する crate 比較
- SSO を利用して ratatui のメモリ効率と実行効率を最適化した話
- compact_str crate の実装の最適化の話
- インラインストレージに24バイト全てを使える理由
- 隙間最適化のための工夫
説明を簡潔にするため,特に断りが無い場合 64bit アーキテクチャを前提とします.
Small String Optimization (SSO) とは
Rust の可変長文字列型 String は文字列バッファへのポインタ,文字列の長さ,バッファのキャパシティの3つのフィールド(8 + 8 + 8 = 24バイト)から成っており,文字列はヒープ上に確保された文字列バッファに置かれます.
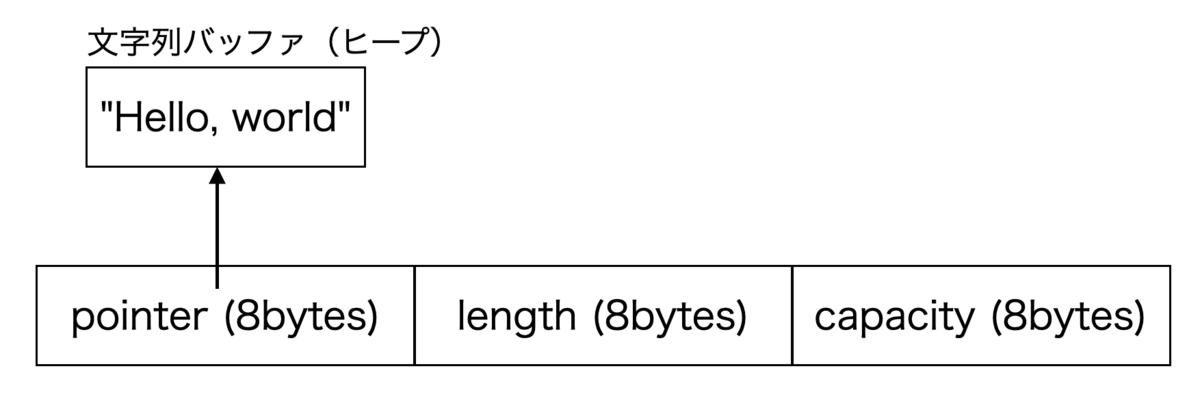
文字列が十分に短い場合,わざわざヒープに確保しなくても24バイトの構造体の中に直に(インラインに)文字列を置けば良いというのが Small String Optimization (SSO) の基本的なアイデアです.

上記の図は典型的な SSO の実装例です.下記のように,文字列長が23バイトまでとそれ以降で構造を使い分けます.
- 文字列長が23バイトよりも長いとき → 標準の
Stringのように文字列をヒープ上のバッファに置く.ポインタを構造体の一番最後のフィールドに置く.ポインタの最下位ビットは常に 0 なので,構造体の最後のバイトの最下位ビットをフラグとし 0 なら文字列をヒープに保存していることを表すことにする. - 文字列長が23バイトまで → 文字列を構造体の中にインラインに置く.最後の1バイトを除く構造体の頭から23バイトが利用可能.最後の1バイトは文字列長とフラグを保存するのに使う,最下位ビットはフラグとし 1 ならインラインに文字列を保存していることを表すことにする.残りの7ビットに文字列の長さを保存する(高々23文字なので過剰)
この最適化には下記のような利点があります.
- 文字列が短いうちはメモリ使用量が少なくて済みます.23バイトの文字列を表すのに,標準の
Stringだと少なくとも47バイトかかりますが,SSO を利用した文字列型では24バイトしかかかりません - 文字列が短いうちはヒープアロケーションを避けられる分速いです.また,構造体内に文字列を直接置くので,キャッシュの局所性も上げることができます
- 標準の
String型と構造体のサイズが変わりません(24バイト)
一方で下記のような欠点もあります.
- 文字列を構造体にインラインで置いているのかヒープに置いているのかで分岐が必要になる
- 標準の文字列型をサードパーティのライブラリもしくは自前の実装に置き換える必要がある
文字列をヒープに置いている場合は標準の String と構造が同じなので,分岐の分のオーバーヘッドがかかる分だけ不利になります.プログラムのロジック的に文字列がほとんどの場合インラインに置けるほど短いことが分かっている時に効果的です.
ちなみに C++ 標準の std::string の実装では SSO が利用されているため,C++ で std::string を使うと自動的に SSO の恩恵を受けることになります.
Rust で SSO を利用できる crate
Rust には SSO を利用した独自の文字列型を提供するサードパーティ製の crate が複数あります.下記は今回考慮した crate のリストです
- smartstring : 比較的素朴な実装の SSO 文字列型を提供
- compact_str : かなり最適化された実装の SSO 文字列型を提供.メンテ・開発が活発
- smol_str : rust-analyzer で使われている文字列型.コピーオンライト(実際に文字列が変更されるまで文字列バッファのコピーを行わない)な実装になっており,文字列のクローンが O(1) でできる.一般的な用途には ecow のほうが良いと作者自身がコメントしていた
- ecow : 参照カウントでコピーオンライトな実装の文字列型を提供.文字列のクローンが O(1) ででき,サイズが 2 words(16バイト)しかない.typst の内部実装で使われている.名前の由来は eco + cow = ecow ?
各 crate が提供する文字列型の機能比較を下記の表にまとめました.
| 型のサイズ | インライン文字列の最大サイズ | クローンの効率 | |
|---|---|---|---|
標準 String |
24バイト | - | O(n) |
| smartstring | 24バイト | 23バイト | O(n) |
| compact_str | 24バイト | 24バイト | O(n) |
| smol_str | 24バイト | 23バイト | O(1) |
| ecow | 16バイト | 15バイト | O(1) |
これらの crate 全てに共通する点として,標準の String を置き換えて簡単に使えるよう,標準の String の API と互換性を持たせています.このおかげで,最小限の労力でこれらの crate を導入することができます.
今回のケースではコピーオンライトな実装は不要だったので,compact_str を使うことにしました.インラインに文字列を置く際に24バイトすべてを使うことができる理由はcompact_str の実装の最適化の話の章で説明するので気になる方は読んでみてください.
ecow は非常に凝った実装ですが,アトミックな参照カウントの上下や参照カウントおよびキャパシティをヒープに保存する分のオーバーヘッドを考慮する必要があります.
前述の通り String との API の互換性により簡単に試せるので,実際に導入してパフォーマンスの変化を見るのが重要です.パフォーマンスが改善できない場合は構造が最もシンプルでサードパーティの依存を増やさない標準の String を使うのがベストです.
ratatui を最適化した話
ratatui とは
ratatui は Terminal User Interface (TUI) アプリを実装するためのライブラリで,GUI フレームワークのようにウィジェットを組み合わせることでターミナル上での UI を構築できます.C でいう ncurses が比較的近いかもしれません.以前は tui-rs というプロジェクトだったのですが,メンテが止まってしまったのでコミュニティベースで fork して ratatui という crate として開発が継続されています.僕も tui-textarea というテキストエディタ機能を提供するウィジェットを開発しています.
前章で説明した通り,今回は ratatui の内部構造を compact_str を使って最適化しました.
ratatui の内部構造の最適化
ratatui はターミナル上の1文字を Cell という単位で保持しています.
例えば下記のような UI を表示している時,
┌───┐ │abc│ └───┘
バッファは下記のような単純な構造で保持されています.
vec![ Cell("┌"), Cell("─"), Cell("─"), Cell("─"), Cell("┐"), Cell("│"), Cell("a"), Cell("b"), Cell("c"), Cell("│"), Cell("└"), Cell("─"), Cell("─"), Cell("─"), Cell("┘"), ]
ここでのポイントは「1文字」というのが Unicode の書記素クラスタ単位であるということです.書記素クラスタは👨👩👧👦絵文字が有名なように複数のコードポイントで成るので,Rust の char で保持することはできず,Cell は内部で1文字ごとに String で文字列を持ちます.
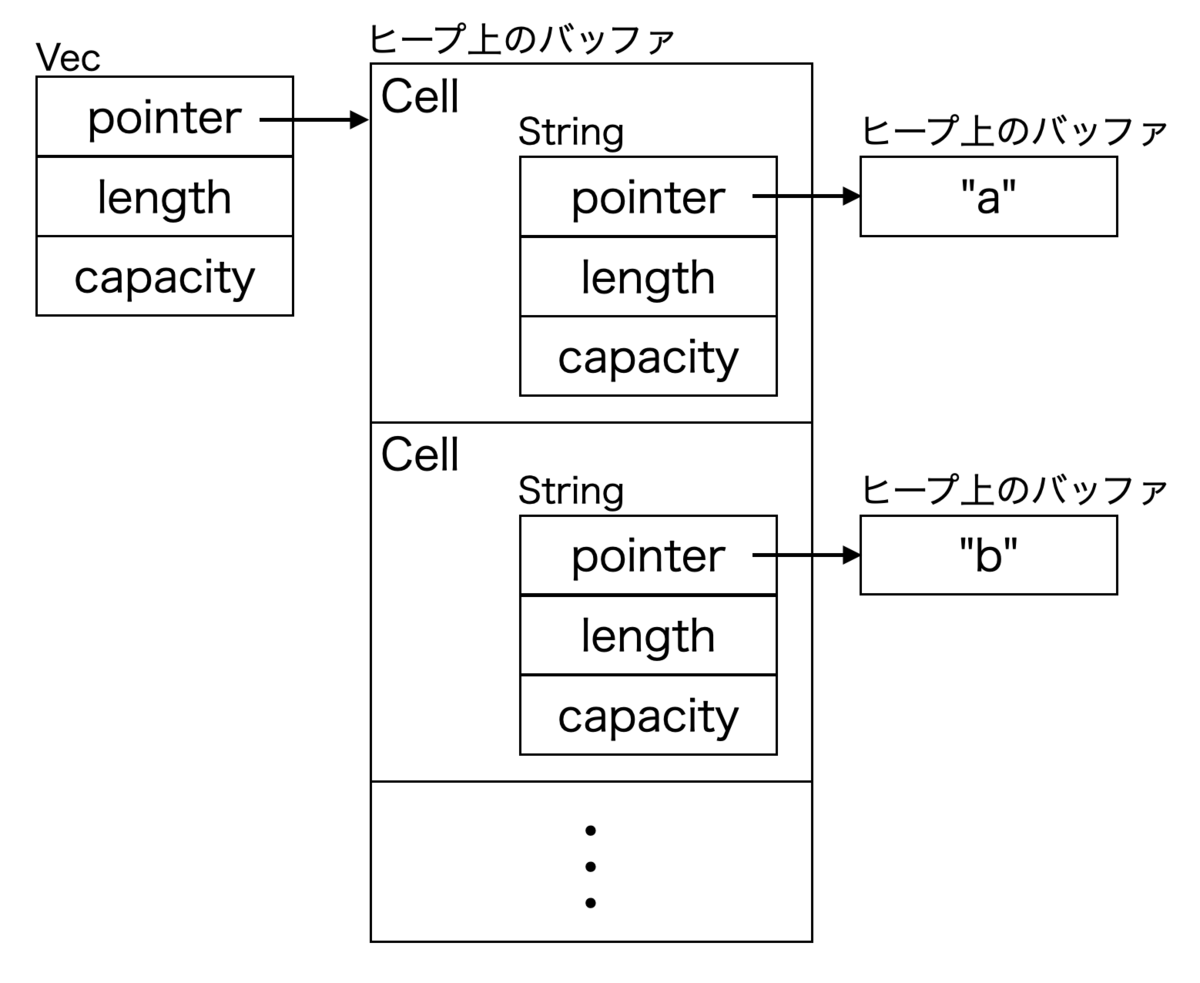
つまり,大量の Cell の1つごとに小さいヒープ割当が発生してしまいます.Cell が持つ文字列はほぼ全てのケースで24バイトに収まるので,これを SSO で最適化した文字列型を用いて最適化するのは妥当に見えます.下記のように文字列はすべて Vec の要素のバッファにインラインで保存できるはずです.
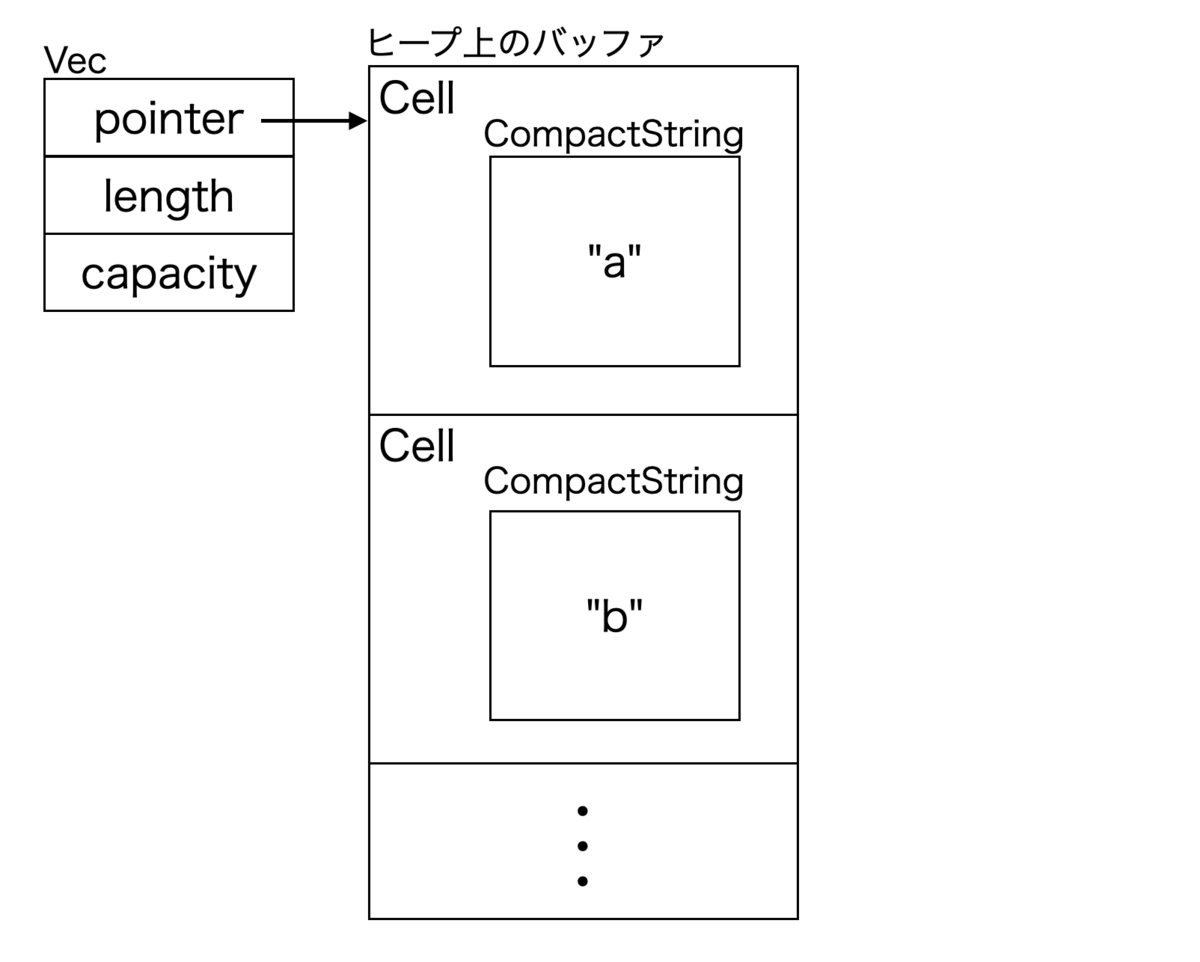
これにより下記のような改善が期待できます.
- ヒープ割り当てのサイズを減らせる(メモリ使用量改善)
- ヒープ割り当ての回数を減らせる(初期化時およびリサイズ時のパフォーマンス改善)
- メモリの局所性を上げられる(キャッシュ効率改善)
macOS でメモリ使用量を計測する方法
CPU プロファイラは結構色々選択肢があるのですが,メモリプロファイラは実はあまりメジャーな方法が無く検索しても情報が少なかったのでやり方を簡単に説明します.Linux はおそらく perf mem でメモリプロファイルが取れるのですが,VirtualBox 上の VM では PMU イベントが取れず利用できなかったので,別の方法を検討しました.
Xcode の Instruments をコマンドラインから利用します.まずは対象のバイナリをビルド
cargo build --example demo --release
次に xctrace コマンドによりインストルメンテーションを有効にしてバイナリを実行します.テンプレートには Allocations を使います.
xctrace record --template Allocations --launch -- ./target/release/examples/demo
注意点として,xctrace はプログラムの標準入出力を奪ってしまう問題があります.ratatui はターミナルのバックエンドを切り替える仕組みがあるので,標準入出力を使わないようにテスト用のバックエンドに実装を直接書き換えることで回避しました.
実行が完了するとカレントディレクトリにトレースファイルが生成されるので,後はそれを開けば Xcode 上で計測結果を解析することができます.
open Launch_demo_2023-10-28_21.18.03_AF4F797C.trace
最適化の効果の計測
ratatui の PR で実際に計測した結果を説明します.計測対象には demo example を利用しました.
メモリ使用量
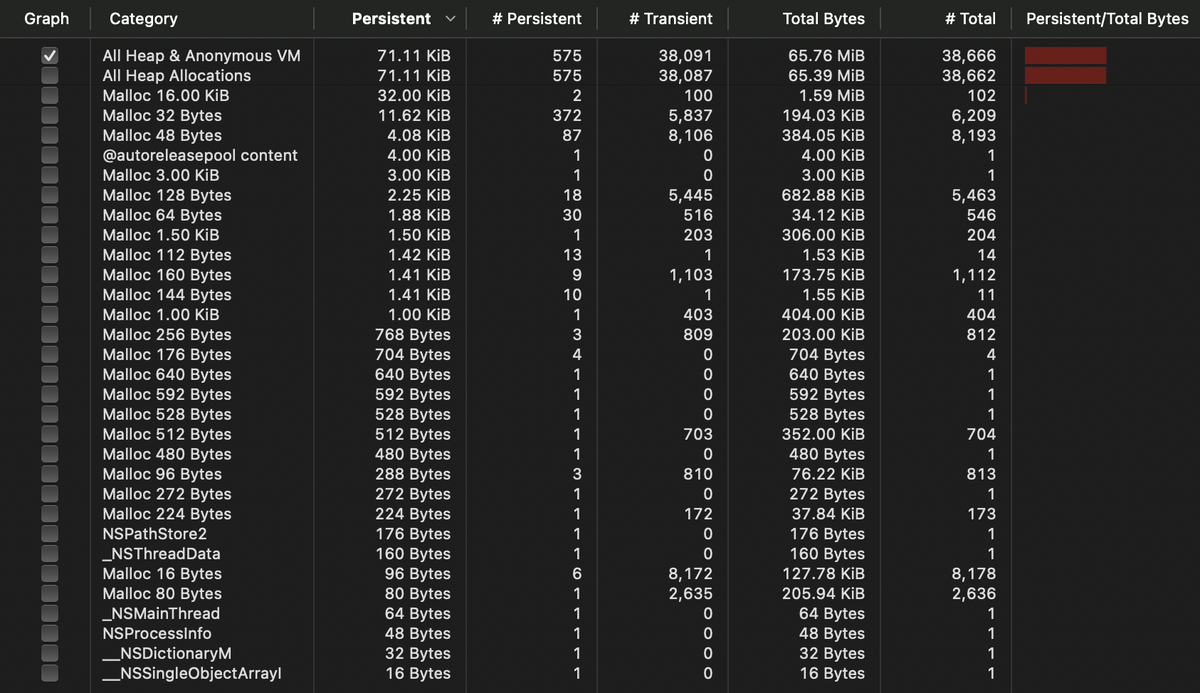
計測対象のアプリで 100 tick 分の描画中に発生したメモリアロケーションを計測しました.
狙い通り16バイト単位のアロケーションの回数が288895回から8178回に大幅に減り,結果として割り当てられたメモリのサイズも 4.41Mib から 127.78Kib へ約35分の1と大幅に減少しました.
main branch |
sso branch |
|
|---|---|---|
| Total bytes | 4.41MiB | 127.78KiB |
| # of allocs | 288895 | 8178 |
| Screenshot | 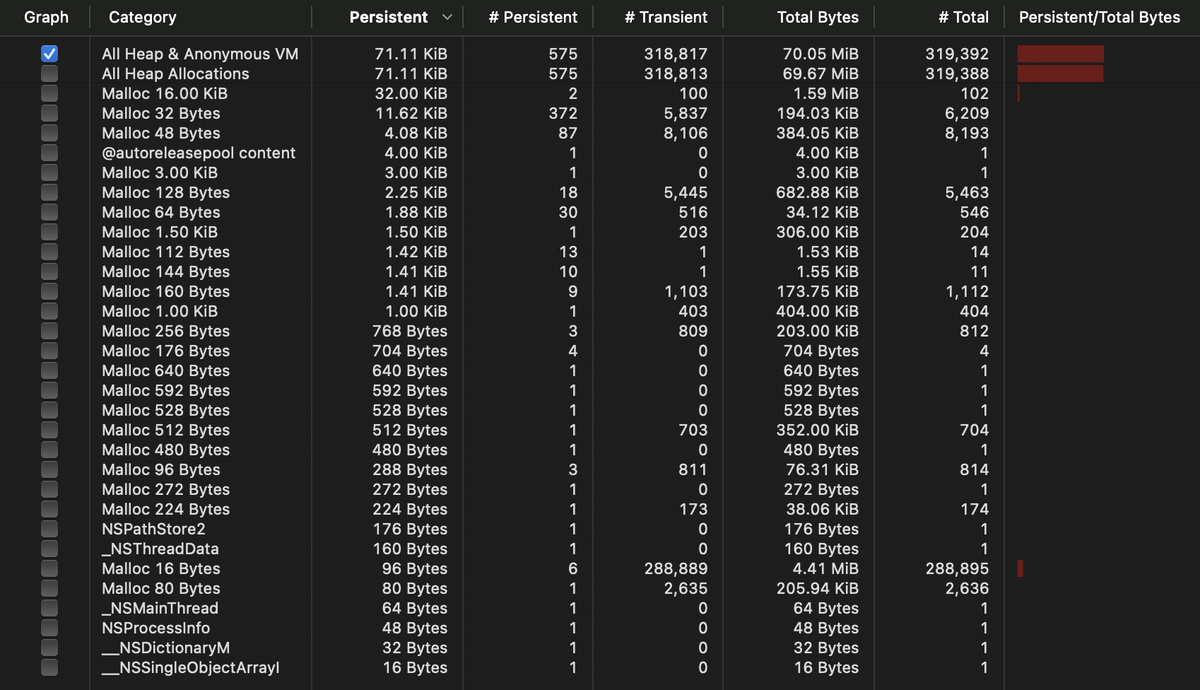 |
 |
CPU 実行効率
実行時間を hyperfine で計測しました.100 tick 分の描画にかかった時間と,初期化時のヒープ割り当て減少による改善を見たかったので最初の tick のみの描画にかかった時間の2通りを計測しました.demo_main が main ブランチをビルドしたバイナリで,demo_sso が今回改善を入れたブランチをビルドしたバイナリです.
100 tick 分の実行効率は 1.14 倍高速化しました.
$ hyperfine ./demo_main ./demo_sso
Benchmark 1: ./demo_main
Time (mean ± σ): 85.2 ms ± 2.5 ms [User: 81.8 ms, System: 2.1 ms]
Range (min … max): 82.2 ms … 94.9 ms 34 runs
Benchmark 2: ./demo_sso
Time (mean ± σ): 74.9 ms ± 0.6 ms [User: 72.2 ms, System: 1.5 ms]
Range (min … max): 73.3 ms … 76.8 ms 38 runs
Summary
./demo_sso ran
1.14 ± 0.03 times faster than ./demo_main
最初の tick のみだと 1.77 倍高速化しました.初期化時のヒープ割り当ての影響が大きいためだと思います.
$ hyperfine --shell=none ./demo_main ./demo_sso
Benchmark 1: ./demo_main
Time (mean ± σ): 8.8 ms ± 0.4 ms [User: 6.4 ms, System: 1.5 ms]
Range (min … max): 8.4 ms … 11.4 ms 316 runs
Benchmark 2: ./demo_sso
Time (mean ± σ): 5.0 ms ± 0.1 ms [User: 3.0 ms, System: 1.1 ms]
Range (min … max): 4.7 ms … 5.8 ms 581 runs
Summary
./demo_sso ran
1.77 ± 0.09 times faster than ./demo_main
compact_str の実装の最適化の話
ここでは compact_str crate が内部で行っている最適化のうちのいくつかについて説明します.これ以外にも分岐無し命令を利用した最適化など,吐かれる機械語を意識した細かい最適化がたくさん行われています.コードコメントがかなり丁寧に入っているので,そのあたりに興味がある人はぜひコードを読んでみてほしいです.
24バイト全てをインライン文字列に使う
Rust で SSO を利用できる crate の章で書いた通り,compact_str の提供する文字列型 CompactString は標準の String に合わせてサイズが24バイトになるように実装されています.一方で,構造体内にインラインに保存できる文字列のサイズも24バイトです.Small String Optimization (SSO) とは の章で書いた通り,SSO を素朴に実装すると,「今文字列をインラインに保存しているかどうか」を示すためのフラグ(と現在の文字列の長さ)に1バイト必要になり,構造体内にインラインに保存できる文字列のサイズは23バイトになるはずです.
CompactString は保存される文字列が UTF-8 でエンコードされていることを利用し,24バイト中の最後の1バイト内にフラグをエンコードしています.
文字列をインラインに保存している場合,24バイト目は必ず UTF-8 文字シーケンスの最後の1バイトになっています.UTF-8 文字シーケンスの最後の1バイトは0〜255の範囲全てを利用していません.なので,未使用の範囲をフラグに充てることができます.CompactString では,この未使用の範囲に文字列のサイズと「今文字列をインラインに保存しているかどうか」のフラグを割り当てています.(注: 実際は静的ストレージに保存された文字列(&'static str)をコピーせずに扱う最適化も絡んでもう少し複雑なのですが,ここでは説明を簡単にするためそれを省いています)
| 値の範囲 | 意味 |
|---|---|
| 0〜127 | ASCII 文字(1バイト) |
| 128〜191 | 非 ASCII 文字シーケンスの最後の1バイト |
| 192〜215 | 現在の文字列の長さ(24バイトなので0〜23) |
| 216 | 文字列がヒープに保存されていることを示すマーカー |
文字列の長さを表す範囲は16進数表現で 0x11000000 から 0x11010111 なので,左から1ビット目と2ビット目を落とせば文字列のサイズを取り出すことができます.
これにより,構造体24バイトのうち最後の1バイトを失うこと無く,下記のようにフラグと文字列のサイズと最大24バイトの文字列を同時に保持することができます.
最後の1バイトの値 b の条件 |
最後の1バイトの意味 | 文字列のサイズ |
|---|---|---|
b < 192 |
UTF-8 文字列の一部 | 24バイト |
192 <= b && b <= 215 |
文字列のサイズ | 0〜23バイト |
b >= 216 |
文字列はヒープに確保されているフラグ | 25バイト以上 |
一方で,ヒープに文字列を保存している場合(つまり文字列のサイズが24バイトを超える場合)は構造体内の最後のバイトを216以上とする必要があります.そのため,Small String Optimization (SSO) とは の章で書いたようなポインタの最下位ビットにフラグを持つということはできません.
CompactString ではヒープに文字列を保存している場合は構造体内の最後のフィールドであるキャパシティについて,下記のような実装になっています.
- 64bit OS の場合 → 文字列のキャパシティを1バイト削り7バイトとしている.これにより標準の
Stringのキャパシティ8バイトと比べて表せる文字列のサイズは72057594037927934バイト(約64ペタバイト)に減るが,そもそもそんな大きなサイズのメモリをプロセスが確保することはできないので問題なし - 32bit OS の場合 → 文字列のキャパシティを1バイト削り3バイトとすると文字列の最大サイズが16777214バイトとなり,現実的にこれを超えることができてしまう.なので,それを超える場合はキャパシティもヒープ上に置くようにする
32bit OS の場合の具体的な実装は話が細かすぎるのでここには書きませんが,気になる方は capacity.rs を読んでみてください.
隙間最適化を行えるようにする内部構造の工夫
隙間最適化(niche optimization)とは,隙間(ニッチ)をうまく埋めるようにフラグの有効値を配置することで構造体のサイズを抑える最適化です.(関連ドキュメント)
一番単純な具体例として Option<bool> を考えると,bool は1バイトの値で 0 が false,1 が true です.さらに Option は Some か None のどちらを取るかをフラグとして持つのでここでも1バイト必要になり,Option<bool> は素朴に考えるとサイズは2バイト必要になります.これを最適化して Some(false) を 0,Some(true) を 1,None を 2 とすることでサイズを1バイトに抑えることができます.
use std::mem::*; println!("{}", size_of::<Option<bool>>()); // => 1 let some_false: u8 = unsafe { transmute(Some(false)) }; let some_true: u8 = unsafe { transmute(Some(true)) }; let none: u8 = unsafe { transmute(<Option<bool>>::None) }; println!("{}", some_false); // => 0 println!("{}", some_true); // => 1 println!("{}", none); // => 2
標準でも NonNull や NonZeroU32 など,隙間最適化を意識した型が提供されています.また,enum を定義するとフラグに使わない無効な値の範囲が発生します.複雑な型では enum な型が深くネストしたりするため,この最適化が多重に行われ構造体のサイズを何バイトも節約することができます.メモリが比較的高価な組み込み環境などで使われることを Rust が想定していることや,Copy を実装するかどうかの基準がその構造体のサイズであることを考えると重要な最適化です.
前章でも書いたように CompactString は文字列を構造体にインラインに保存する場合,その24バイト全てを文字列に利用します.そのため下記のように単純に24バイトの配列として構造を定義してしまうとコンパイラは隙間最適化を行うことができません.
struct Repr([u8; 24]);
一方で,前章で書いたように CompactString の24バイト中最後の1バイトには未使用の範囲がまだ存在します.その範囲があることをコンパイラに伝えると隙間最適化ができるようになるはずです.
そのため,compact_str では CompactString の内部の構造体定義を下記のように工夫しています.(実際のコード)
struct Repr( // 最初の8バイト *const (), // 次の8バイト usize, // 最後の8バイト u32, u16, u8, LastByte, )
最後の LastByte は1バイトの enum 型で,定義は下記のようになっています.(実際のコード)
#[repr(u8)] enum LastByte { Ascii0 = 0, Ascii1 = 1, Ascii2 = 2, // ... Ascii127 = 127, MutiByte128 = 128, MutiByte129 = 129, MutiByte130 = 130, // ... MutiByte191 = 191, Len0 = 192, Len1 = 193, Len2 = 194, // ... Len23 = 215, Heap = 216, Static = 217, // 本記事では説明していない &'static str 向けの最適化のためのフラグ }
これにより,コンパイラはこの enum の定義を通じて「CompactString の24バイト目は218〜255が未使用の範囲(無効値)である」と認識することができ,この範囲を隙間最適化に利用できるようになります.結果として,例えば CompactString のサイズと Option<CompactString> のサイズが同じになります.
まとめ
本記事では下記の3点について書きました
- Small String Optimization (SSO) とは何か,Rust で SSO の恩恵を受けるにはどうすれば良いか
- 実際に ratatui という Rust ライブラリを SSO を用いて改善した結果
- 16バイトブロックのメモリ割り当て量が32分の1に減少
- 初期化時の実行効率が1.7倍速,平常時の描画の実行効率が1.1倍速
- SSO を利用した文字列型を提供する compact_str crate がどのように実装を工夫しているか
もし「小さい文字列を大量に割り当てる」というユースケースに心当たりがある場合はこの最適化の導入を検討してみてはどうでしょうか?優秀なサードパーティライブラリのおかげで容易に導入できるので,メモリプロファイラや CPU プロファイラを用いて複数のライブラリを比較検討することができます.
えっちな grep をつくった
H(uman-friendly) な grep コマンド hgrep をつくりました.
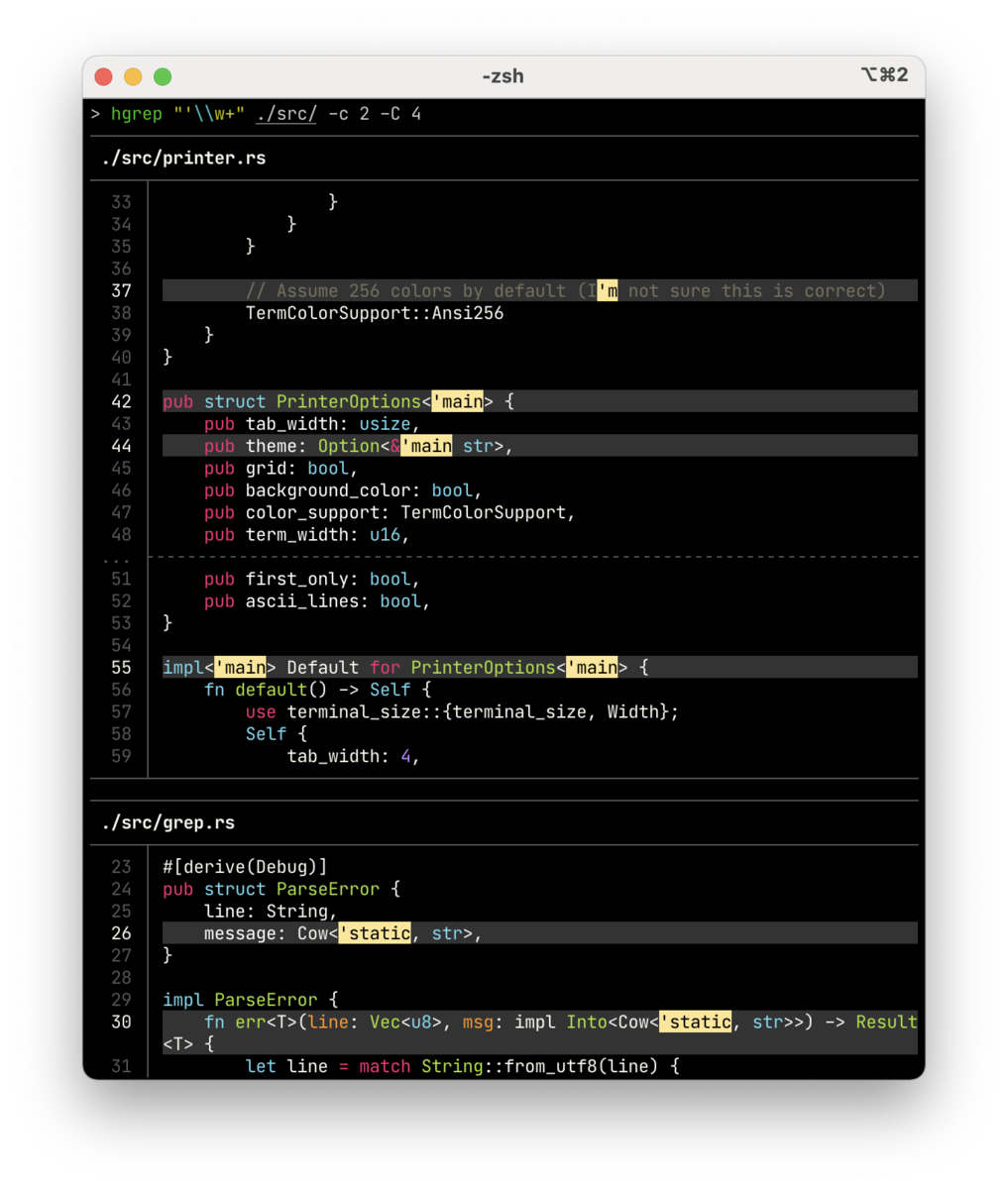
ファイルを特定のパターンで検索し,マッチした箇所を構文ハイライトしたコード片で表示します.超ざっくり言うと,ripgrep で検索して bat でマッチ箇所付近を表示するような感じです.
grep -C によるコンテキスト表示に似ていますが,マッチ行が近い時は1つのコード片にまとめる,周囲何行を表示するかをヒューリスティックに少し賢く決めているなど,ちょっと出力は工夫しています.
動機
手元のリポジトリでコードを検索する時は
- 単純に grep で検索してマッチ結果を眺める
grep | fzfのように検索結果をfzfで絞り込んだりプレビューするvim $(grep -l ...)のように検索結果をエディタで開く
あたりを使い分けているのですが,マッチ結果全体を個々のマッチの周囲を見ながら眺めるというのがやりにくいと常々思っていました.
要は GitHub のコード検索結果のような出力を手元でも見たいなというのが,hgrep を使った動機です.
インストール方法
- リリースページから zip をダウンロードして解凍し,なかに入っている実行ファイルを
/usr/local/binなどにコピーしてください. cargoを使ってcargo install hgrepでインストールできます.ソースからビルドする場合は feature flags を使って自分のほしい機能だけを有効にしてインストールすることもできます(バイナリサイズや依存パッケージを減らせる).- Homebrew (macOS もしくは Linux),MacPorts(macOS),pkgin(NetBSD)などのパッケージマネージャもサポートしています.
詳しくはドキュメントを参照してください.
使い方
ripgrep と同じように使えます.普段 rg コマンドを使ってるなら,それを hgrep に置き換えるだけでほぼ問題ないと思います.
hgrep [options] pattern [path...]
例えば ./src 以下の なんとかPrinter を検索したければ
hgrep '\w+Printer' ./src
のようにするとマッチ箇所のコードスニペット一覧が出力されます.
また,grep -nH の出力を標準入力から受け取ることもできます.hgrep ではサポートできていない検索方法を使いたい時や,一旦ファイルに保存したり加工した結果を表示する時に便利です.
grep -nH pattern -R [path...] | hgrep
例えば ./src 以下の なんとかPrinter を検索したければ
grep -nH '\w+Printer' -R ./src | hgrep rg -nH '\w+Printer' ./src | hgrep
カスタマイズ
プリンタを指定する
hgrep はコード片をハイライトして表示するのに使うプリンタ実装が syntect と bat の2つあり,--printer オプションで指定できます.
初めは bat を表示部分に使おうと思っていたのですが,パフォーマンスや出力結果に色々不満が出てきてしまったので,結局 syntect で自前実装したという経緯があり,特に理由が無ければ syntect がおすすめです.
batプリンタの2倍〜4倍ほど高速- マッチ範囲がハイライトされるなど,出力やレイアウトが
hgrep向けに最適化されている - より多くのカラーテーマに対応
--backgroundオプションによる背景色の描画(batはカラーテーマの背景色を反映しない)- ターミナル互換性周りの改善(├ や ┬ などの unicode 文字がうまく表示できないターミナル向けのオプションや16色しか使えないターミナルへの対応)
syntect プリンタにはこれらの利点があります.
カラーテーマを選ぶ
--list-themes オプションを使うと各カラーテーマのプレビューを表示できるので,その中から気に入ったテーマを見つけることができます.
# 背景色なしでプレビュー hgrep --list-themes # 背景色ありでプレビュー hgrep --list-themes --background
デフォルトの Monokai の他にも30種類のカラーテーマが用意されています.
また,あまりカラフル過ぎると見づらいという人向けに,Cyanide や Carbonight などの色数を抑えたカラーテーマもあります
| ayu-dark | ayu-mirage | ayu-light |
|---|---|---|
 |
 |
 |
| Carbonight | predawn | Material |
|---|---|---|
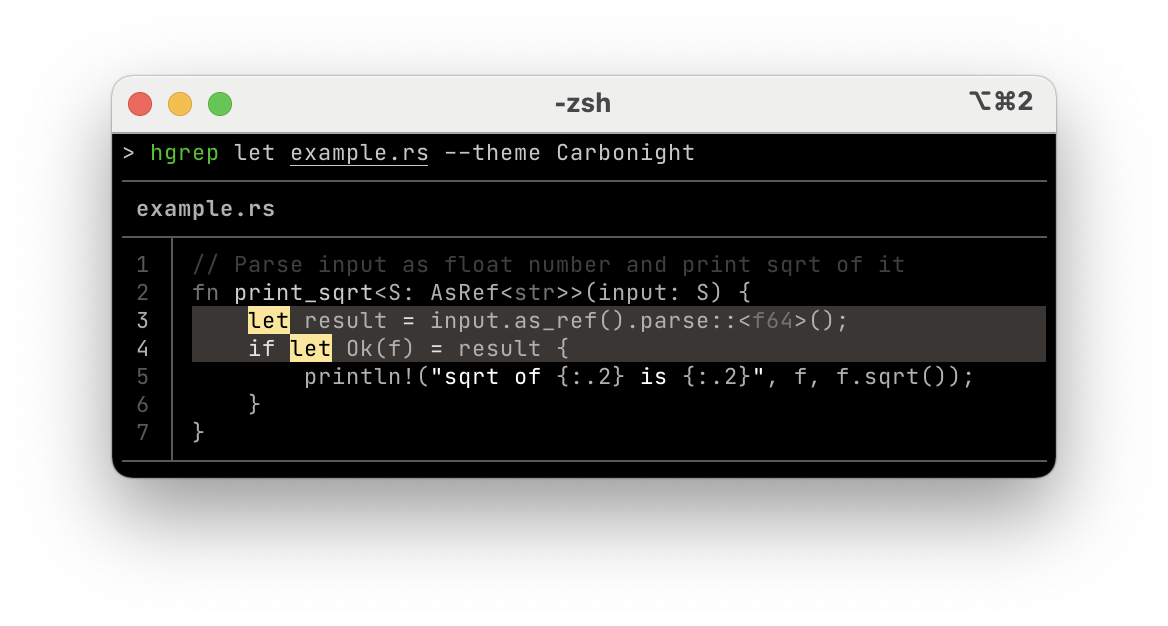 |
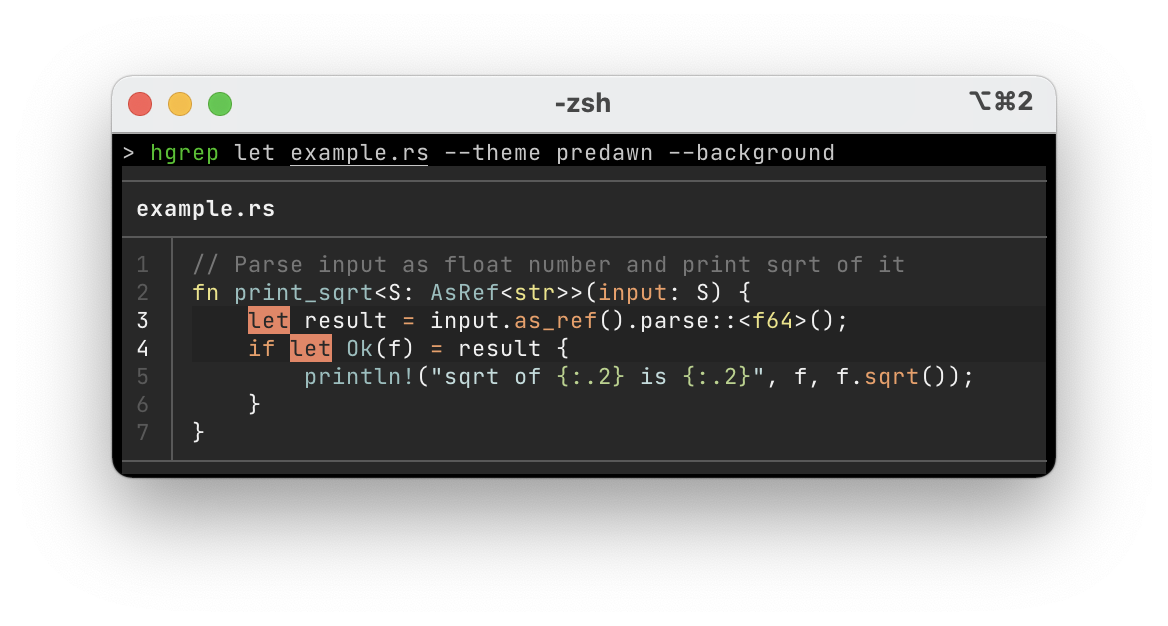 |
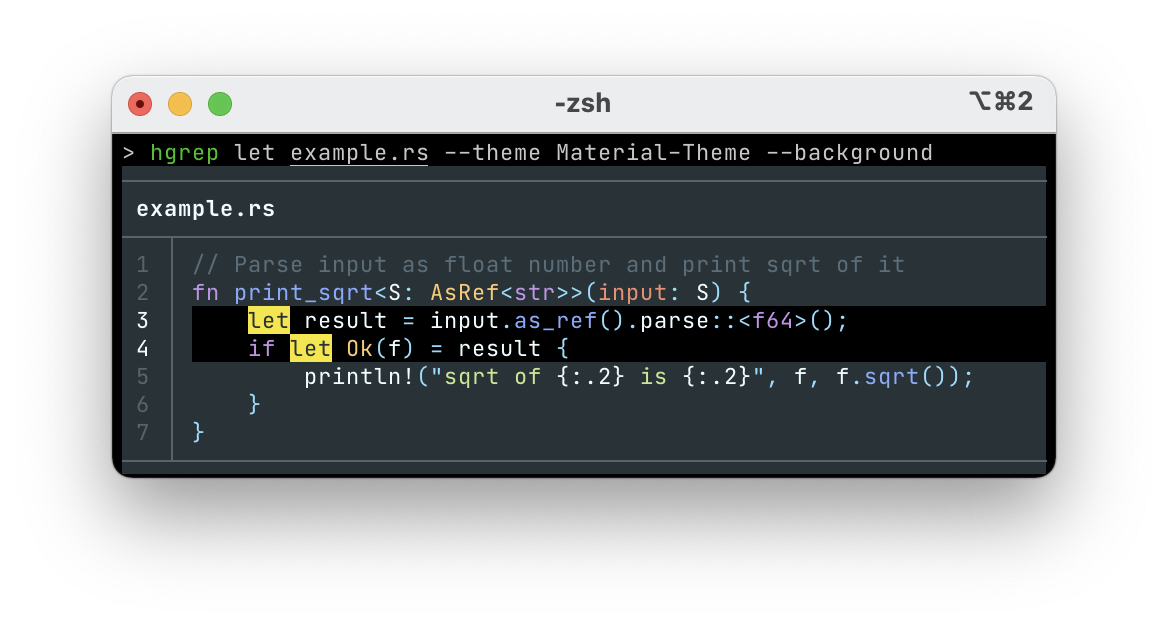 |
デフォルトで使うオプションを指定する
シェルの alias コマンドを使って,hgrep コマンドを上書きしてください.
# --hidden: 隠しファイルを検索対象にする # --theme: ayu-dark をカラーテーマに使う # --background: 背景色を描画する alias hgrep='hgrep --hidden --theme ayu-dark --background'
これを例えば bash なら .bash_profile あたりに設定しておくと良いと思います.
また,less などの pager を使いたい場合は,下記のように関数を使って hgrep コマンドを上書きしてください.
# less を使ってページングする function hgrep() { command hgrep --term-width "$COLUMNS" "$@" | less -R }
標準出力を別プロセスにつなぐとターミナルのウィンドウサイズが分からなくなるので,--term-width と $COLUMNS で明示的に指定する必要があります.
コマンド補完
--generate-completion-script オプションでシェルの補完スクリプトを標準出力に出力します.これを補完スクリプトに設定することで,オプションなどの補完が効くようになります.
# Zsh を使っていて set comps=~/.zsh/site-functions している場合 hgrep --generate-completion-script zsh > ~/.zsh/site-functions/_hgrep
Bash,Zsh,Fish,PowerShell,Elvish に対応しています.
実装周りの話
依存ライブラリ
rayon,ripgrep,syntect あたりをライブラリとして使ってます.
- rayon: 有名なお手軽データ並列処理ライブラリ.便利すぎる.
- ripgrep: Rust から
rgコマンドとほぼ同等の機能・パフォーマンスの grep 実装を直接使うことができます.ライブラリとしてもよく整備されています. - syntect: シンタックスハイライトするためのライブラリです.Sublime Text のハイライト定義やカラーテーマを使うことができ,多くのカラーテーマや言語ごとの構文ハイライトルールの資産を使うことができます.さらに,複数のスレッドで並列にハイライト処理を行えるようにもなっていて(後述),よくできてます.
パフォーマンス
最初は ripgrep と bat をライブラリとして使い,ripgrep の検索結果を bat の bat::PrettyPrinter で表示する小さいツールを考えていたのですが,残念ながらパフォーマンスが満足のいくものになりませんでした.
問題はコードをハイライトして出力する部分で,
- そもそも構文ハイライトは重い処理です.大量の正規表現マッチを繰り返してコードの各部分のハイライト色を決定します
- 正確に構文ハイライトするにはファイルの頭から順番にハイライトを計算していく必要があります.なのでファイルの後ろに行くほど時間がかかります
- 構文ハイライトに使うハイライトルール定義を合計で数 MB ほどロードする必要があります
これらを直接解決するのは難しいので,十分なパフォーマンスを出すために,処理を並列化することにしました.そこで rayon を使い,ファイル単位でスレッドを割り当ててファイル内検索(grep)→ コード片にまとめる処理 → ハイライトの計算 を並列で行って,最後に出力処理だけは直列化して行っています.
ここで前述の syntect の並列ハイライト対応をうまく活かすことができました.残念ながら bat::PrettyPrinter は並列に使える実装になってませんでした.
syntect を使った場合 |
bat を使った場合 |
|---|---|
 |
 |
これによってハイライト処理が劇的に速くなり,2倍以上高速化しました.
マルチスレッド絡みのバグ
syntect で並列にハイライト処理をした時だけごく稀にクラッシュする問題を見つけて修正したりしました.普段使いでは一度だけ再現したクラッシュバグで,その後ベンチマークで高速で初期化→入力→描画の処理をひたすら繰り返すと10回に1回程度の頻度で再現させることができ,スレッド数を1に絞ると再現しなくなるというものでした.
該当箇所だけを抜き出すとこんな感じです.
use lazycell::AtomicLazyCell; struct X { cell: AtomicLazyCell<Regex>, } impl X { fn new() -> Self { Self { cell: AtomicLazyCell::new() } } fn get_regex(&self) -> &T { if let Some(x) = self.cell.borrow() { x } else { let regex = ...; self.cell.fill(regex).ok(); self.cell.borrow().unwrap() } } }
lazycell は値の初期化を遅らせる機能を提供するライブラリで,AtomicLazyCell は最初「空」の状態で初期化され,fill() が呼ばれた時に初めて初期化されます(初期化より前に値を取ろうとするとクラッシュします).borrow() はすでに初期化された値があればその値への参照を Some で返し,そうでなければ None を返します
get_regex() メソッドは「cell が初期化されていればすでにある値を返し,初期化されていなければ値を生成して cell を初期化してから値を返す」というメソッドです.クラッシュを起こしたのは self.cell.borrow().unwrap() の部分で,直前で fill を呼んでいるにも関わらず borrow() が None を返しているということを示しています.
このバグは2つ以上のスレッドがほぼ同時に self.cell.fill(regex) を実行した場合にのみ起こります.AtomicLazyCell は内部でロックを取って値を初期化するスレッドを1つに限定しているのですが,
- スレッド1が
fill()の呼び出しを開始 - スレッド1が
fill()の呼び出し内部で cell のロックを取得 - スレッド2が
fill()の呼び出しを開始 - 既にスレッド1が cell のロックを取得しているのでスレッド2はロックを取れない
fill()はロックが取れなかった場合は諦める実装になっているので,スレッド2はfill()から return する- スレッド2はすぐに次の行の
borrow()を実行する.しかしこの時,スレッド1はまだ cell に値をセットできていない.そのためborrow()はNoneを返す(後続のunwrap()でクラッシュ)
という流れでした.
これは lazycell が,fill() で値を初期化しに逝く時に既にロックを誰かが取っていると即諦める仕様になっているのが問題なので,once_cell を使うことで解決できました.
once_cell は複数スレッドが同時に1つの cell を初期化しようとした時,処理をキューイングして後に来たほうを(busy loop で)待たせる実装になっているのでこの問題は起こりません.busy loop なので,待たされている側のスレッドが長時間待たされると計算資源を食いつぶしてまずいですが,少なくとも今回は Regex の初期化でそこまで時間がかかる処理ではなかったので問題ありませんでした.
まとめ
Human-friendly な出力の grep コマンド,hgrep をつくりました.完全に自分の使いたいユースケースに向けてつくってますが,もしよければ試してみてください.とりあえず欲しい機能はすべて揃っている状態です.
パフォーマンスは現時点でも問題ないですが,コード片の範囲を決める計算を O(n) から O(1) に落とす,ハイライトルール定義の読み込みを遅延する,構文ハイライトを計算する範囲を削ってハイライト処理をサボるなどいくつかアイデアはあるので,時間がある時にでも試しに実装してみようかなと思ってます.
actionlint v1.4 → v1.6 で実装した新機能の紹介
前回の actionlint の記事 GitHub Actions のワークフローをチェックする actionlint をつくった からちょうど1ヶ月経ち,今日 v1.6.0 をリリースしました.前回時点では v1.4.0 で,そこから v1.4.1, v1.4.2, v1.4.3, v1.5.0, v1.5.1, v1.5.2, v1.5.3, v1.6.0 とリリースを重ねています.git diff によると v1.4.0 〜 v1.6.0 で
155 files changed, 14816 insertions(+), 2981 deletions(-)
のコード変更を行ったようです.
この記事では大きめの機能追加や改善をいくつか紹介します.
- 有名アクションの input/output チェック
- スクリプトインジェクション脆弱性のチェック
-formatオプションによる柔軟なエラー出力- ドキュメントの再構成
- Windows でカレントディレクトリの実行ファイルが意図せず実行できてしまう脆弱性への対処
- Playground の機能追加
変更の完全な履歴についてはチェンジログを確認してください.
有名アクションの input/output チェック
アクションには入力と出力があり,action.yml メタデータに定義されています.入力には必須のものと必須でないものがあります.
これらの input/output についての情報は,そのアクションの action.yml をフェッチしないと分かりません.ネットワークリクエストは遅いですし,ネットワークが制限された環境(コンテナ内など)でも使えるようにする必要があるため,フェッチするのは避けたいです.そのため,事前に有名なアクションの action.yml の情報をクロールしてコード生成で持っておくことで,input/output のチェックを実現しています.簡単な調査では,有名なアクションのチェックさえできれば全体アクション実行の9割以上はカバーできそうなので,とりあえずこれでヨシとしています.
on: push jobs: test: runs-on: ubuntu-latest steps: - uses: actions/cache@v2 # ERROR: 必須の input "key" がない with: # ERROR: 定義されていない input keys: | ${{ hashFiles('**/*.lock') }} ${{ hashFiles('**/*.cache') }} path: ./packages - run: make
この例は actions/cache の input のチェックをしています.actions/cache は key という必須の input があるのでそれが指定されていないこと,action.yml に定義されていない keys input が指定されていることの2点がエラーとして報告されます.
on: push jobs: test: runs-on: ubuntu-latest steps: # ERROR: id: cache のステップはまだ実行されていない - run: echo ${{ steps.cache.outputs.cache-hit }} - uses: actions/cache@v2 id: cache with: key: ${{ hashFiles('**/*.lock') }} path: ./packages # OK - run: echo ${{ steps.cache.outputs.cache-hit }} # ERROR: cache_hit という output は存在しない - run: echo ${{ steps.cache.outputs.cache_hit }}
この例は actions/cache の output のチェックをしています.actions/cache はキャッシュがヒットしたかどうかを cache-hit という output にセットします.actionlint では steps.cache.outputs のオブジェクト型に action.yml に基づいてプロパティを定義することで,型チェックで正しい output を使えているかをチェックします.ここでは存在しない cache_hit プロパティにアクセスしようとしてエラーになっています.また,steps.cache.outputs の型は,id: cache のステップ以降でのみ定義されるので,id: cache より前のステップではアクセスできずエラーになります.
action.yml の情報はスクリプトを組んで go generate で更新するようにしていて,毎週 CI で実行され,更新があれば自動で pull request が生成される仕組みになっています.
スクリプトインジェクション脆弱性のチェック
GitHub Actions の ${{ }} は単に文字列として置換されます.例えば
- run: echo '${{ github.event.pull_request.title }}'
という step があると,ジョブ実行時に ${{ }} の中身が評価されて置換され,
- run: echo 'pull request のタイトル'
がスクリプトとして実行されます.
ここで悪意のあるユーザが '; malicious_command ... というタイトルで pull request を作成するとどうなるでしょう?
- run: echo ''; malicious_command ...
と置換され,malicious_command が実行できてしまいます.ジョブ実行時には設定されたパーミッションで credential が生成されますし,フックによってはシークレットにアクセスすることもできますので,秘匿情報を盗むことができてしまいます.
これを防ぐためには
- run: echo "$TITLE" env: TITLE: ${{ github.event.pull_request.title }}
というように環境変数を通してアクセスする回避策があります.
ここでの問題は github.event.pull_request.title が信頼できない入力であるという点です.どの入力が信頼できないかは,GitHub Security Lab のブログ記事に一覧があります.
actionlint では,run: などのスクリプトインジェクションの危険がある箇所で,これらの信頼できない入力が ${{ }} で直に使われていないかをチェックします.
on: pull_request jobs: test: runs-on: ubuntu-latest steps: - name: Print pull request title # ERROR: 信頼できない入力の使用 run: echo '${{ github.event.pull_request.title }}' - uses: actions/stale@v4 with: repo-token: ${{ secrets.TOKEN }} # OK: アクションの入力はスクリプトに直接渡されないので使って良い stale-pr-message: ${{ github.event.pull_request.title }} was closed - uses: actions/github-script@v4 with: # ERROR: この入力はスクリプトで評価される script: console.log('${{ github.event.head_commit.author.name }}')
このチェックは @azu さんに機能リクエストをいただいて実装しました.
-format オプションによる柔軟なエラー出力
Go テンプレート構文を使ってエラーメッセージの出力フォーマットを柔軟に指定できるようにしました.構文を知っている人向けに説明すると,. はエラーオブジェクトのスライスになっていて,各エラーオブジェクトの .Message や .Line フィールドなどを利用して出力を整形します.
例えば,
actionlint -format '{{json .}}'
とすると json アクションを通してエラーメッセージの列が JSON 文字列化され
[{"message":"unexpected key \"branch\" for ...
のようにオブジェクトの配列で出力されます.出力を jq などで操作するのに便利です.
また,もう少し複雑な例として,
actionlint -format '{{range $err := .}}### Error at line {{$err.Line}}, col {{$err.Column}} of `{{$err.Filepath}}`\n\n{{$err.Message}}\n\n```\n{{$err.Snippet}}\n```\n\n{{end}}'
とすると Markdown 形式でエラーを出力でき
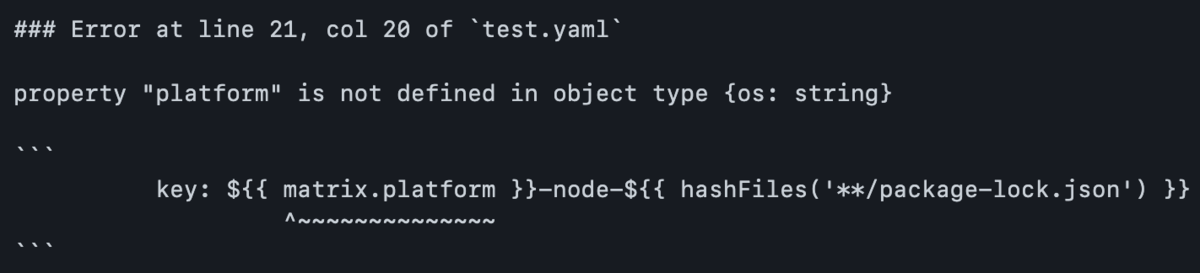
のようにエラーが出力されます.
ドキュメントでは ::error コマンドを使ってエラーアノテーションを付ける例やフォーマットの使い方についても説明していますので,詳しくはそちらを参照してください.
この機能は @ybiquitous さんに機能リクエストをいただいて実装しました.
ドキュメントの再構成
以前はすべてのドキュメントをリポジトリ直下の README.md にすべて突っ込んでいたのですが,チェック項目やセクション数が増えてきて非常に長くなってしまっていました.長い README は読まれないので,ドキュメントの内容ごとにファイルを分けて整理しました.
README.md: イントロダクション,簡単なチュートリアル,他のドキュメントへのリンク,ライセンスについてのみ記載していますdocs/checks.md: actionlint が行うすべてのチェック項目のリストです.ワークフロー例とエラー出力例,Playground へのリンクをチェック項目ごとに記載していますdocs/install.md: インストール方法です.ビルド済みバイナリ,Homebrew,ダウンロードスクリプト,go installによるソースからのビルドのそれぞれについて説明していますdocs/usage.md:actionlintコマンドの使い方(特定のエラーを無視する方法,-formatオプションの使い方,exit status の意味など),Playground の使い方について説明しています.また,reviewdog, Problem Matchers, super-linter との連携についても解説していますdocs/config.md: コンフィグファイルの使い方について説明していますdoc/api.md: actionlint を Go のライブラリとして使う方法について解説していますdoc/reference.md: 各種リソースへのリンク集です
Windows でカレントディレクトリの実行ファイルが意図せず実行できてしまう脆弱性への対処
Windows では foo というように絶対パスではないコマンドを実行すると,カレントディレクトリにある foo.exe を実行できてしまうという挙動があります.Go の exec.LookPath("foo") でもカレントディレクトリの foo.exe を返してしまいます.
actionlint でも shellcheck コマンドや pyflakes コマンドのパスを取得するのに exec.LookPath を使っていたので,カレントディレクトリに shellcheck.exe や pyflakes.exe があるとそちらを意図せず実行してしまう問題がありました.現在は execabs を使うことでこの問題を修正済みです.
Playground の機能追加
https://rhysd.github.io/actionlint/
actionlint を Wasm にビルドすることでブラウザ上でも動くようにした Playground ですが,より手軽に使えて共有できるようにいくつか改善を行いました.

- 'Permalink' ボタンを設置しました.これをクリックすると今のコードエディタのソースの状態を URL のハッシュにエンコードすることで永続化します.バグ報告時に Playground で再現させてそのパームリンクを提供してもらえると助かるなと思って実装しています.
- URL の入力フォームを設置しました.URL を入力してから Check ボタンを押すと,URL 先のファイルをフェッチしてきます.もちろんですが GitHub Pages からフェッチできる URL のみ使えます.
https://github.com/owner/repo/tree/branch/...: GitHub 上の特定のファイルをブラウザで表示させた時の URLhttps://raw.githubusercontent.com/owner/repo/branch/...: GitHub 上でホストされている生のファイルの URLhttps://gist.github.com/owner/...: Gist 上の特定のファイルをブラウザで表示させた時の URLhttps://gist.githubusercontent.com/owner/...: Gist 上でホストされている生のファイルの URL
まとめ
前回の記事以降も継続して改善・機能追加を行っていきました.もしよければ試しに使ってみて,何か改善点・問題点などあれば issue で教えてもらえるとありがたいです(日本語でも英語でも大歓迎です).